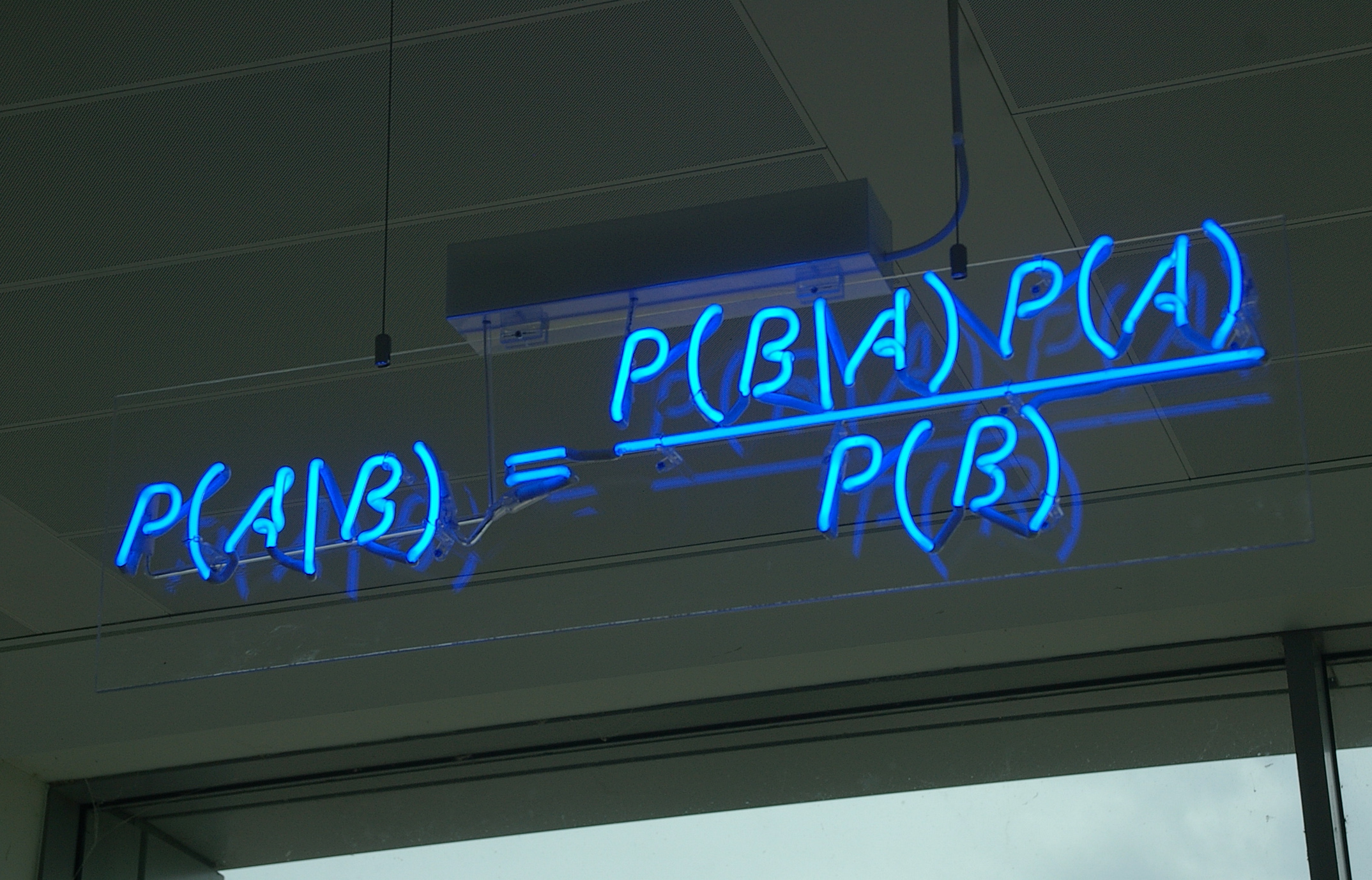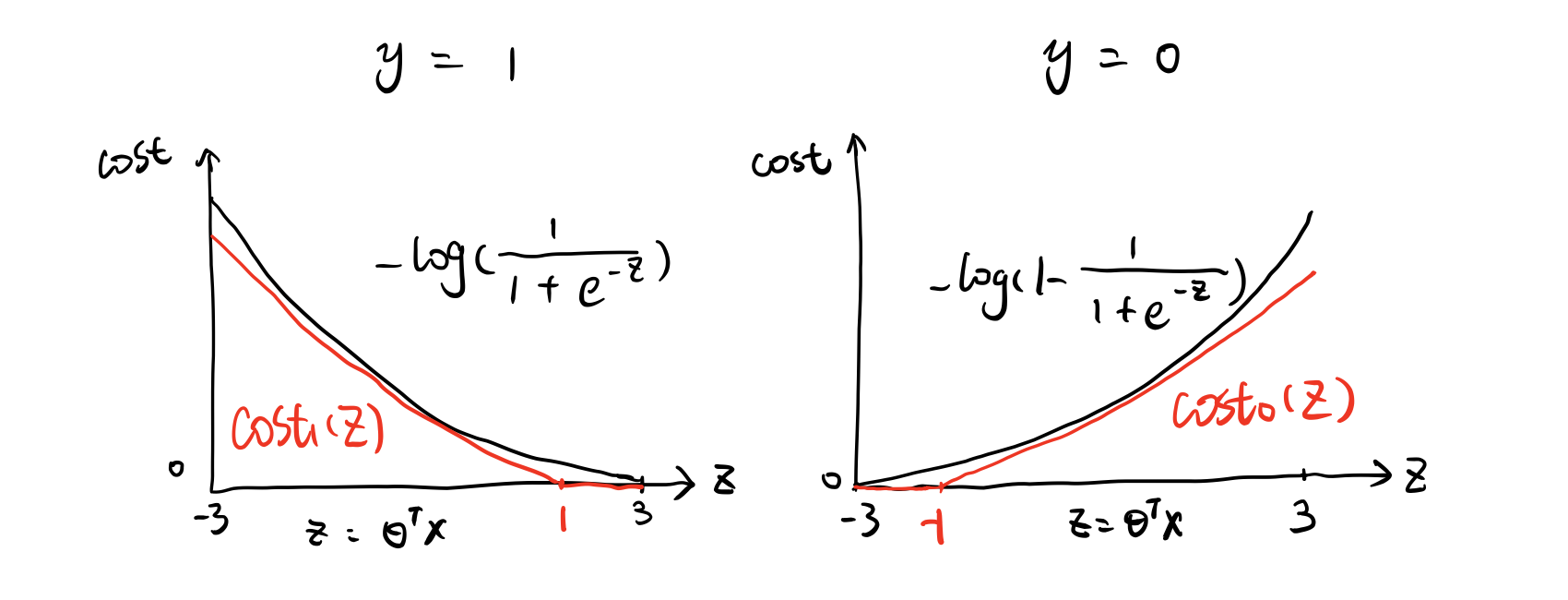机器学习算法
目录
线性回归
线性回归到底是什么? 假设数据为:D = ( x 1 , y 1 ) , ⋯ , ( x N , y N ) D = (x_1,y_1), \cdots , (x_N,y_N) D = ( x 1 , y 1 ) , ⋯ , ( x N , y N ) X = ( x 1 , x 2 , ⋯ , x N ) T , Y = ( y 1 , y 2 , ⋯ , y N ) T X = (x_1,x_2,\cdots,x_N)^T,Y = (y_1,y_2,\cdots, y_N)^T X = ( x 1 , x 2 , ⋯ , x N ) T , Y = ( y 1 , y 2 , ⋯ , y N ) T h ( x ) = h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ N x N = θ T X h(x) = h_\theta(x) = \theta_0+\theta_1x_1+\theta_2x_2+\cdots+\theta_Nx_N = \theta^TX h ( x ) = h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ N x N = θ T X
x 1 , ⋯ , x N x_1, \cdots,x_N x 1 , ⋯ , x N θ \theta θ θ \theta θ J ( θ ) J(\theta) J ( θ ) h θ ( x ) h_\theta(x) h θ ( x )
核心思想 所以如何构造J ( θ ) J(\theta) J ( θ ) 损失函数 就十分重要!
最小二乘法
我们采用二范数定义的平方误差来定义损失函数:
J ( θ ) = ∑ i = 1 N ∣ ∣ θ T x i − y i ∣ ∣ 2 2 J(\theta) = \sum_{i=1}^{N} ||\theta^Tx_i-y_i||_2^2 J ( θ ) = i = 1 ∑ N ∣ ∣ θ T x i − y i ∣ ∣ 2 2 J ( θ ) = ( θ ) T X T X θ − 2 θ T X T Y + Y T Y J(\theta) = (\theta) ^TX^TX\theta-2\theta^TX^TY+Y^TY J ( θ ) = ( θ ) T X T X θ − 2 θ T X T Y + Y T Y θ ^ \hat{\theta} θ ^ θ ^ = a r g min θ J ( θ ) \hat\theta = arg\min \limits_{\theta} J\left(\theta\right) θ ^ = a r g θ min J ( θ ) θ \theta θ θ ^ \hat{\theta} θ ^ θ ^ = ( X T X ) − 1 X T Y = X + Y \hat{\theta} = (X^TX)^{-1}X^TY=X^+Y θ ^ = ( X T X ) − 1 X T Y = X + Y normal equation ,其中的θ ^ = ( X T X ) − 1 X T \hat{\theta} = (X^TX)^{-1}X^T θ ^ = ( X T X ) − 1 X T X X X X = U Σ V T X=U\Sigma V^T X = U Σ V T X + = V Σ − 1 U T X^+=V\Sigma^{-1}U^T X + = V Σ − 1 U T
在几何角度上
这里,最小二乘法相当于直线与实验值的距离的平方和,我们希望这个距离越小越好,也就是所谓点到直线的最短距离,就是垂直的情况。那么延伸到高维的情况,假设我们的实验样本张成一个p维空间(满秩):X = S p a n ( x 1 , ⋯ , x N ) X = Span(x_1, \cdots , x_N) X = S p a n ( x 1 , ⋯ , x N ) h ( x ) = h θ ( x ) = θ T X h(x) = h_\theta(x) = \theta^TX h ( x ) = h θ ( x ) = θ T X x 1 , ⋯ , x N x_1, \cdots , x_N x 1 , ⋯ , x N X T ⋅ ( Y − θ T X ) = 0 ⇒ θ = ( X T X ) − 1 X T Y X^T \cdot (Y-\theta^TX) = 0 \Rightarrow \theta = (X^TX)^{-1}X^TY X T ⋅ ( Y − θ T X ) = 0 ⇒ θ = ( X T X ) − 1 X T Y
梯度下降法
J ( θ ) = 1 2 ∑ i = 1 N ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2} \sum_{i=1}^{N} (h_\theta(x^{(i)})-y^{(i)})^2 J ( θ ) = 2 1 i = 1 ∑ N ( h θ ( x ( i ) ) − y ( i ) ) 2 θ \theta θ J ( θ ) J(\theta) J ( θ )
首先对参数随机赋值
改变参数,使得损失函数按梯度下降的方向减少,梯度方向有偏导决定,因为求的为极小值,所以梯度方向是偏导的反方向,迭代方式有两种:
重复直到收敛
选用误差函数为平方和的概率解释 至于为什么我们把损失函数定义为上述的形式,我们从概率方面来解释。假设根据特征的预测结果和实际结果有误差ϵ ( i ) \epsilon^{(i)} ϵ ( i ) y ( i ) = θ T x ( i ) + ϵ ( i ) y^{(i)}=\theta^Tx^{(i)}+\epsilon^{(i)} y ( i ) = θ T x ( i ) + ϵ ( i ) p ( y ( i ) ∣ x ( i ) ; θ ) = 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi}\sigma}exp\Big(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\Big) p ( y ( i ) ∣ x ( i ) ; θ ) = 2 π σ 1 e x p ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) J ( θ ) = l o g p ( Y ∣ X ; θ ) = l o g ∏ i = 1 N p ( y ( i ) ∣ x ( i ) ; θ ) J(\theta) = log \space p(Y|X;\theta) = log \space \prod_{i=1}^{N}p(y^{(i)}|x^{(i)};\theta) J ( θ ) = l o g p ( Y ∣ X ; θ ) = l o g i = 1 ∏ N p ( y ( i ) ∣ x ( i ) ; θ ) a r g min θ J ( θ ) = a r g min θ ∑ i = 1 N ( y ( i ) − θ T x ( i ) ) 2 arg\min \limits_{\theta} J(\theta) = arg\min \limits_{\theta} \sum_{i=1}^{N}(y^{(i)}-\theta^Tx^{(i)})^2 a r g θ min J ( θ ) = a r g θ min i = 1 ∑ N ( y ( i ) − θ T x ( i ) ) 2
线性回归的优缺点
优点:
建模速度快:不需要复杂计算,数据量大时运行速度很快
可根据洗漱给出每个变量的解释
缺点:
改进 正则化
针对过拟合情况,我们有以下选择:
加数据
特征选择
正则化L 1 : a r g min θ J ( θ ) + λ ∣ ∣ θ ∣ ∣ 1 , λ > 0 L1: arg\min \limits_{\theta}J(\theta)+\lambda||\theta||_1,\lambda>0 L 1 : a r g θ min J ( θ ) + λ ∣ ∣ θ ∣ ∣ 1 , λ > 0 L 2 : a r g min θ J ( θ ) + λ ∣ ∣ θ ∣ ∣ 2 2 , λ > 0 L2: arg\min \limits_{\theta}J(\theta)+\lambda||\theta||_2^2,\lambda>0 L 2 : a r g θ min J ( θ ) + λ ∣ ∣ θ ∣ ∣ 2 2 , λ > 0
L1 Lassoλ \lambda λ
L2 Ridgeλ \lambda λ
补充:
实际应用和代码展示 小结 线性回归模型是最简单 的模型,但是麻雀虽小,五脏俱全,在这里,我们利用最小二乘误差得到了闭式解。同时也发现,在噪声为正态分布的时候,MLE的解等价于最小二乘误差,而增加了正则项后对模型过拟合情况进行改善,分别介绍了Lasso和Ridge的特点和区别。
虽然线性模型简单且易于理解,但是也有很多局限性,比如对非线性数据效果不好,对异常值敏感,无法解决分类问题,受制于特征间的线性相关性以及易造成维数灾难等等。
逻辑回归
逻辑回归是什么?为什么要引入? 一句话概括:逻辑回归假设数据服从伯努利分布 ,通过极大似然化函数 的方法,运用梯度下降 来求解参数,从而达到二分类 的目的。
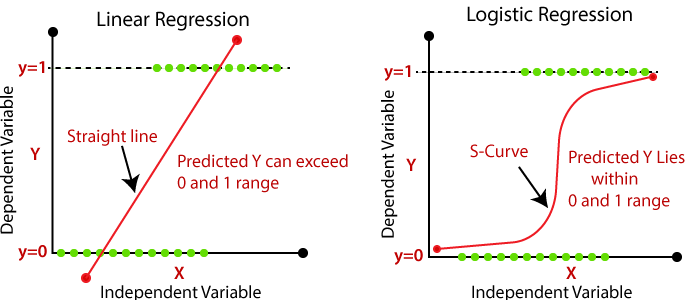
首先逻辑回归虽名为回归,但并不是一个回归方法,它主要用来解决二分类问题,面对分类问题,上文的线性回归显得无能为力,从下图可以看到,线性回归在对作为离散变量存在的y时,只能用直线进行拟合,并且所预测的y可能会超过0到1的范围 ,并且对异常值非常敏感 。
那么我们想引入非线性元素,来解决以上两个问题,我们希望输出的值p ( y = 1 ∣ X ; θ ) p(y=1|X;\theta) p ( y = 1 ∣ X ; θ ) 0 0 0 1 1 1
对一个二分类问题,我们假设:
P r e d i c t = { 1 i f h θ ( x ) ⩾ 0.5 0 i f h θ ( x ) < 0.5
Predict=\left\{
\begin{array}{rcl}
1 & & {if \space h_\theta(x) \geqslant0.5}\\
0 & & {if \space h_\theta(x)<0.5}
\end{array} \right. P r e d i c t = { 1 0 i f h θ ( x ) ⩾ 0 . 5 i f h θ ( x ) < 0 . 5
这里的h θ ( x ) h_\theta(x) h θ ( x ) θ T X \theta^TX θ T X
那么我们如何引入非线性因素来完成二分类任务呢?
核心思想:Sigmoid函数、极大似然估计、损失函数(包含理论推导) 第一部分:Sigmoid函数 我们利用判别模型 来对 p ( y = 1 ∣ X ; θ ) p(y=1|X;\theta) p ( y = 1 ∣ X ; θ )
p ( y = 1 ∣ X ; θ ) = p ( X ; θ ∣ y = 1 ) p ( y = 1 ) p ( X ; θ ∣ y = 1 ) p ( y = 1 ) + p ( X ; θ ∣ y = 0 ) p ( y = 0 )
p(y=1|X;\theta) = \frac{p(X;\theta|y=1) p(y=1)}{p(X;\theta|y=1) p(y=1)+p(X;\theta|y=0) p(y=0)}
p ( y = 1 ∣ X ; θ ) = p ( X ; θ ∣ y = 1 ) p ( y = 1 ) + p ( X ; θ ∣ y = 0 ) p ( y = 0 ) p ( X ; θ ∣ y = 1 ) p ( y = 1 ) a = l n p ( X ; θ ∣ y = 1 ) p ( y = 1 ) p ( X ; θ ∣ y = 0 ) p ( y = 0 ) a = ln\frac{p(X;\theta|y=1) p(y=1)}{p(X;\theta|y=0) p(y=0)} a = l n p ( X ; θ ∣ y = 0 ) p ( y = 0 ) p ( X ; θ ∣ y = 1 ) p ( y = 1 )
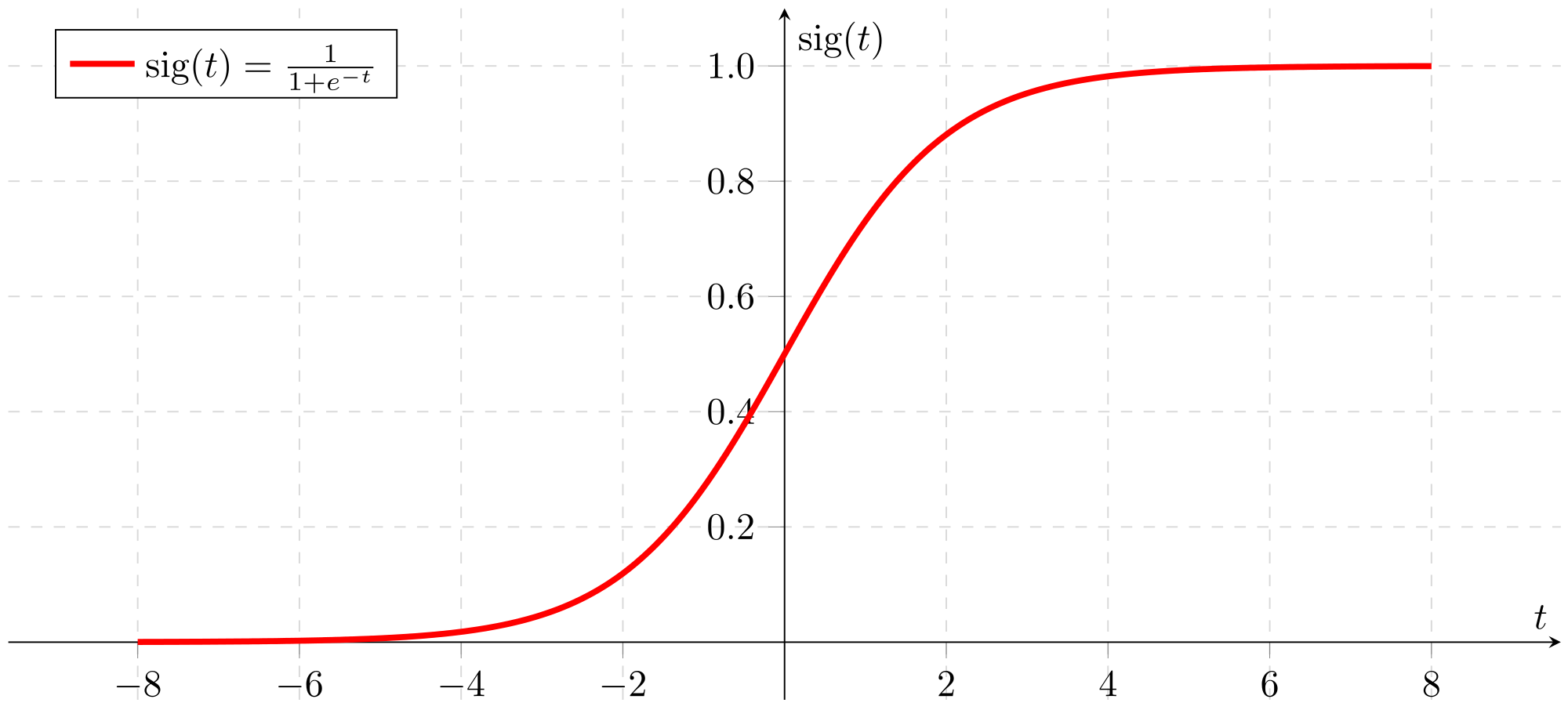
p ( y = 1 ∣ X ; θ ) = 1 1 + e x p ( − a ) p(y=1|X;\theta) = \frac{1}{1+exp(-a)} p ( y = 1 ∣ X ; θ ) = 1 + e x p ( − a ) 1
上面的公式就是所谓的Sigmoid函数,图像如下:
其中的参数表示了两类联合概率比值的对数,我们并不关心这个参数的具体值,因为我们可以关于模型直接对a a a a = θ T X a = \theta^TX a = θ T X
所以,Sigmoid函数就变为了
p ( y = 1 ∣ X ; θ ) = 1 1 + e − θ T X = h θ ( x ) = p 1 p(y=1|X;\theta) = \frac{1}{1+e^{-\theta^TX}}=h_\theta(x)=p_1 p ( y = 1 ∣ X ; θ ) = 1 + e − θ T X 1 = h θ ( x ) = p 1
于是,问题便转化成了找 θ \theta θ 我们不断优化参数来最小化损失函数,找到最优的参数 ,那么概率判别模型常用最大似然估计(MLE) 的方法来确定参数。
第二部分:极大似然估计(MLE)、损失函数 之前总结过,我们假设数据服从伯努利分布,什么是伯努利分布?
伯努利试验是单次随机试验 ,只有 成功(值为1)或 失败(值为0) 这两种结果,在这里也就是随机抽取一个数据点,不是属于第一类(y = 1 y=1 y = 1 y = 0 y=0 y = 0
p ( y ∣ x ; θ ) = p 1 y ( 1 − p 1 ) ( 1 − y ) p(y|x;\theta)=p_1^y(1-p_1)^{(1-y)} p ( y ∣ x ; θ ) = p 1 y ( 1 − p 1 ) ( 1 − y )
这里 y = 1 y=1 y = 1 0 0 0 N N N
p ( y i ∣ x i ; θ ) = h θ ( x i ) y i ( 1 − h θ ( x i ) ) ( 1 − y i ) p(y_i|x_i;\theta)=h_\theta(x_i)^{y_i}(1-h_\theta(x_i))^{(1-y_i)} p ( y i ∣ x i ; θ ) = h θ ( x i ) y i ( 1 − h θ ( x i ) ) ( 1 − y i )
所以对于所有N N N
p ( y ∣ X ; θ ) = ∏ i = 1 N [ h θ ( x i ) y i ( 1 − h θ ( x i ) ) ( 1 − y i ) ] = L ( θ ) p(y|X;\theta)=\prod_{i=1}^{N}[h_\theta(x_i)^{y_i}(1-h_\theta(x_i))^{(1-y_i)}]=L(\theta) p ( y ∣ X ; θ ) = i = 1 ∏ N [ h θ ( x i ) y i ( 1 − h θ ( x i ) ) ( 1 − y i ) ] = L ( θ )
我们对等式两边同时取对数 得到:
l ( θ ) = ∑ i = 1 N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] l(\theta)=\sum_{i=1}^{N}[y_ilog(h_\theta(x_i))+(1-y_i)log(1-h_\theta(x_i))] l ( θ ) = i = 1 ∑ N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ]
从而我们要利用极大似然估计 的方法得到:
θ ^ = a r g max θ l ( θ ) = a r g max θ ∑ i = 1 N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] \hat\theta = arg\max\limits_{\theta}l(\theta)=arg\max\limits_{\theta}\sum_{i=1}^{N}[y_ilog(h_\theta(x_i))+(1-y_i)log(1-h_\theta(x_i))] θ ^ = a r g θ max l ( θ ) = a r g θ max i = 1 ∑ N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ]
这里我们发现,要最大化 l ( θ ) l(\theta) l ( θ ) 最小化 − l ( θ ) -l(\theta) − l ( θ ) 不就是相当于最小化损失函数了么?那么我们终于找到了所谓的损失函数 了!
θ ^ = a r g min θ J ( θ ) = a r g min θ − ∑ i = 1 N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] \hat\theta = arg\min\limits_{\theta}J(\theta)=arg\min\limits_{\theta}-\sum_{i=1}^{N}[y_ilog(h_\theta(x_i))+(1-y_i)log(1-h_\theta(x_i))] θ ^ = a r g θ min J ( θ ) = a r g θ min − i = 1 ∑ N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ]
这里的损失函数为:
J ( θ ) = − 1 N ∑ i = 1 N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] J(\theta)=-\frac{1}{N}\sum_{i=1}^{N}[y_ilog(h_\theta(x_i))+(1-y_i)log(1-h_\theta(x_i))] J ( θ ) = − N 1 i = 1 ∑ N [ y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ]
注意这里的1 N \frac{1}{N} N 1
那么我们继续刚才的推导,我们对于 l ( θ ) l(\theta) l ( θ ) θ \theta θ
∂ l ( θ ) ∂ θ = y i h θ ( x i ) ⋅ ∂ h θ ( x i ) ∂ θ + 1 − y i 1 − h θ ( x i ) ⋅ − ∂ h θ ( x i ) ∂ θ
\frac{\partial l(\theta) }{\partial \theta} = \frac{y_i}{h_\theta(x_i)} \cdot \frac{\partial h_\theta(x_i)}{\partial \theta} + \frac{1-y_i}{1-h_\theta(x_i)} \cdot -\frac{\partial h_\theta(x_i)}{\partial \theta}
∂ θ ∂ l ( θ ) = h θ ( x i ) y i ⋅ ∂ θ ∂ h θ ( x i ) + 1 − h θ ( x i ) 1 − y i ⋅ − ∂ θ ∂ h θ ( x i )
注意到∂ h θ ( x i ) ∂ θ = x i h θ ( x i ) ( 1 − h θ ( x i ) )
\frac{\partial h_\theta(x_i)}{\partial \theta} = x_ih_\theta(x_i)(1-h_\theta(x_i))
∂ θ ∂ h θ ( x i ) = x i h θ ( x i ) ( 1 − h θ ( x i ) )
如果不信的话,可以自己求一下下,比较简单,所以带入后最终结果为
∂ l ( θ ) ∂ θ = ∑ i = 1 N y i ( 1 − p 1 ) x i − p 1 x i + y i p 1 x i = ∑ i = 1 N ( y i − p 1 ) x i
\frac{\partial l(\theta) }{\partial \theta} = \sum_{i=1}^{N}y_i(1-p_1)x_i-p_1x_i+y_ip_1x_i=\sum_{i=1}^{N}(y_i-p_1)x_i
∂ θ ∂ l ( θ ) = i = 1 ∑ N y i ( 1 − p 1 ) x i − p 1 x i + y i p 1 x i = i = 1 ∑ N ( y i − p 1 ) x i
注意这里的 p 1 = h θ ( x i ) p_1 = h_\theta(x_i) p 1 = h θ ( x i ) y = 1 y=1 y = 1 ,这个很重要,一定要搞清楚,记牢固!
思考:
为什么不想线性回归那样定义损失函数呢?在线性回归中,我们有
J ( θ ) = 1 N ∑ i = 1 N 1 2 ( h θ ( x i ) − y i ) 2
J(\theta) = \frac{1}{N}\sum_{i=1}^{N}\frac{1}{2}(h_\theta(x_i)-y_i)^2
J ( θ ) = N 1 i = 1 ∑ N 2 1 ( h θ ( x i ) − y i ) 2
但是如果我们把 h θ ( x i ) = 1 1 + e − θ T x i h_\theta(x_i) = \frac{1}{1+e^{-\theta^Tx_i}} h θ ( x i ) = 1 + e − θ T x i 1
因此我们采用MLE的方法来确定参数!
第三部分:梯度下降法 那么,我们知道对于逻辑回归,损失函数为(一个观测值为例)
J ( θ ) = 1 N ∑ i = 1 N C o s t ( h θ ( x ) , y )
J(\theta) = \frac{1}{N}\sum_{i=1}^{N}Cost(h_\theta(x),y)
J ( θ ) = N 1 i = 1 ∑ N C o s t ( h θ ( x ) , y )
这里的 h θ ( x ) h_\theta(x) h θ ( x ) y y y
C o s t ( h θ ( x ) , y ) = { − l o g ( h θ ( x ) ) i f y = 1 − l o g ( 1 − h θ ( x ) ) i f y = 0
Cost(h_\theta(x),y) =\left\{
\begin{array}{rcl}
-log(h_\theta(x)) & & {if \space y=1}\\
-log(1-h_\theta(x)) & & {if \space y=0}
\end{array} \right.
C o s t ( h θ ( x ) , y ) = { − l o g ( h θ ( x ) ) − l o g ( 1 − h θ ( x ) ) i f y = 1 i f y = 0
上面我们提到了要最小化损失函数,那么要利用到梯度下降法(Gradient Descent)
这里的 α \alpha α m m m 适当选取学习率和批大小对梯度下降的结果,也就是参数确定的结果有非常重要的影响! (后文会深入讨论)
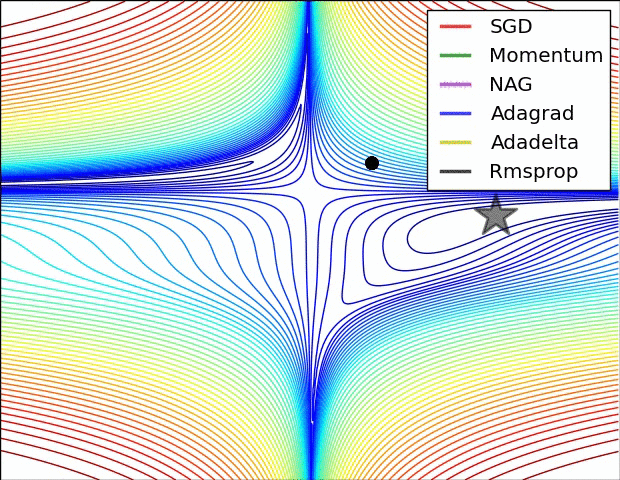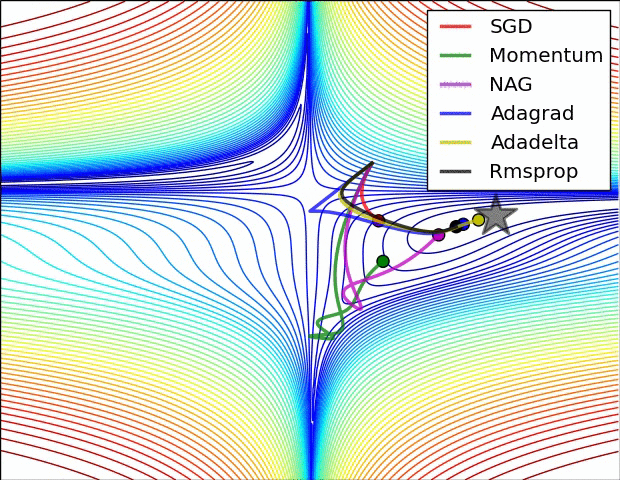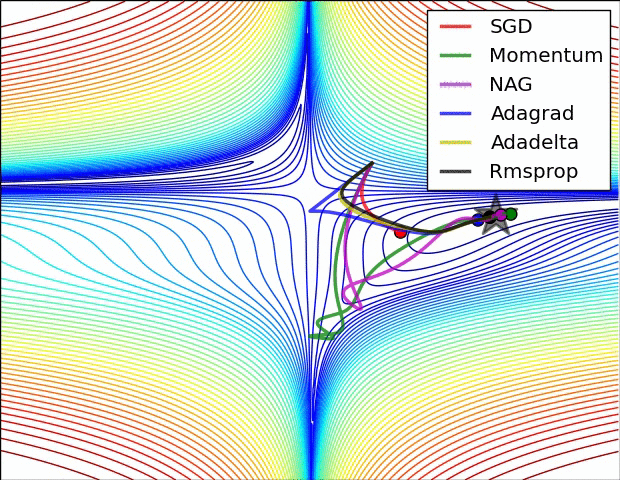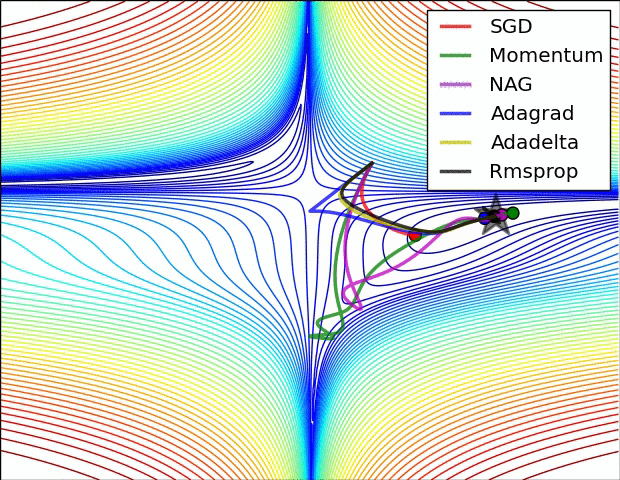
当然,我们不光可以用梯度下降法来进行对损失函数的最小化,我们有多种optimization的选择,多种方法的速度和效率如下图所示:
实际应用和代码展示 逻辑回归面经和其他资料 小结 逻辑回归模型是非常基础 的二分类模型,也是我们接触更多机器学习算法的必经之路,在二分类问题上有非常优秀的表现,但同时也有一些缺点和局限性,比如对很依赖特征工程和特征选择(这个对于模型的结果十分重要!) ,容易欠拟合(模型复杂度不够),对分布很不均匀的数据效果不好等等,最重要的是,当某个或某些特征可以完全对目标类别进行分类时,逻辑回归会表现得很不稳定,也就是其中的 p ( Y = 1 ∣ X ; θ ) = 1 p(Y=1|X;\theta) = 1 p ( Y = 1 ∣ X ; θ ) = 1 l n ( p ( Y = 1 ∣ X ; θ ) 1 − p ( Y = 1 ∣ X ; θ ) ) = θ T X ln(\frac{p(Y=1|X;\theta)}{1-p(Y=1|X;\theta)}) = \theta^TX l n ( 1 − p ( Y = 1 ∣ X ; θ ) p ( Y = 1 ∣ X ; θ ) ) = θ T X
朴素贝叶斯
判别模型与生成模型
判别模型 我们知道,其实机器学习就是想办法从特征 X X X y y y p ( y ∣ X ) p(y|X) p ( y ∣ X )
那么对于判别模型,我们只考虑去估计条件概率,是在有限样本的条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型,也可以理解为在二分类问题中,p ( y = 1 ∣ X ) + p ( y = 0 ∣ X ) = 1 p(y=1|X) + p(y=0|X) = 1 p ( y = 1 ∣ X ) + p ( y = 0 ∣ X ) = 1 1 1 1
生成模型 而生成式模型求得 p ( y , X ) p(y,X) p ( y , X ) X X X
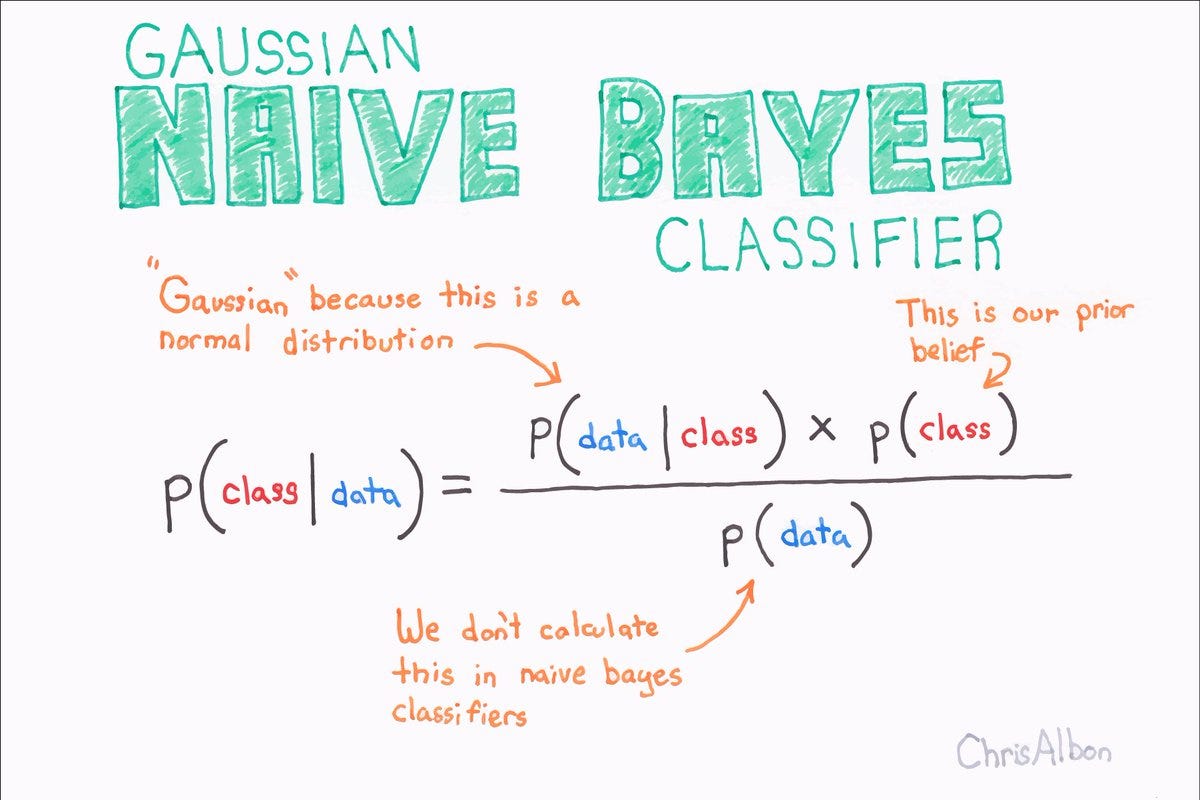
什么是朴素贝叶斯?
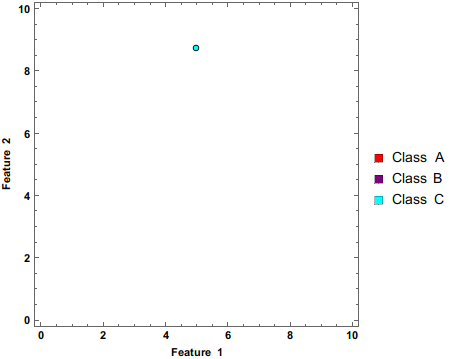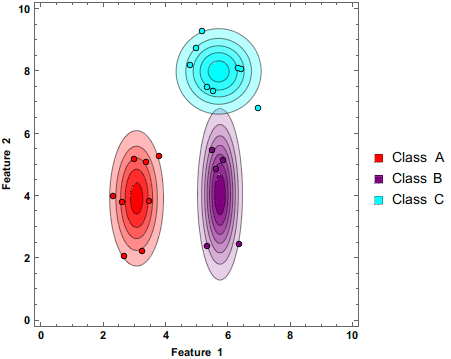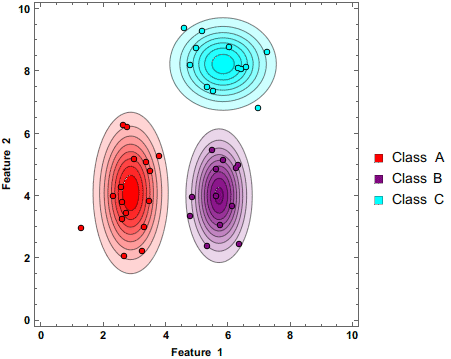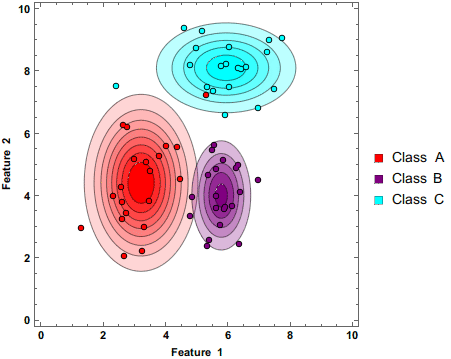
首先,朴素贝叶斯是个生成模型,朴素贝叶斯分类器是一系列以假设特征之间强独立 下运用贝叶斯定理 为基础的简单地概率分类器。
朴素贝叶斯自20世纪50年代已广泛研究。在20世纪60年代初就以另外一个名称引入到文本信息检索 界中,[1] :488 并仍然是文本分类 的一种热门(基准)方法,文本分类是以词频 为特征判断文件所属类别或其他(如垃圾邮件 、合法性、体育或政治等等)的问题。通过适当的预处理,它可以与这个领域更先进的方法(包括支持向量机 )相竞争。[2] 它在自动医疗诊断 中也有应用。[3]
朴素贝叶斯是一种构建分类器的简单方法。该分类器模型会给问题实例分配用特征 值表示的类标签,类标签取自有限集合。它不是训练这种分类器的单一算法,而是一系列基于相同原理的算法:所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关 。举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖 或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。
对于某些类型的概率模型,在监督式学习 的样本集中能获取得非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计 方法;换而言之,在不用到贝叶斯概率 或者任何贝叶斯模型的情况下,朴素贝叶斯模型也能奏效。
尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够获取相当好的效果。2004年,一篇分析贝叶斯分类器问题的文章揭示了朴素贝叶斯分类器获取看上去不可思议的分类效果的若干理论上的原因。[5] 尽管如此,2006年有一篇文章详细比较了各种分类方法,发现更新的方法(如决策树 和随机森林 )的性能超过了贝叶斯分类器。[6]
朴素贝叶斯分类器的一个优势在于只需要根据少量的训练数据估计出必要的参数(变量的均值和方差)。由于变量独立假设,只需要估计各个变量的方法,而不需要确定整个协方差矩阵 。
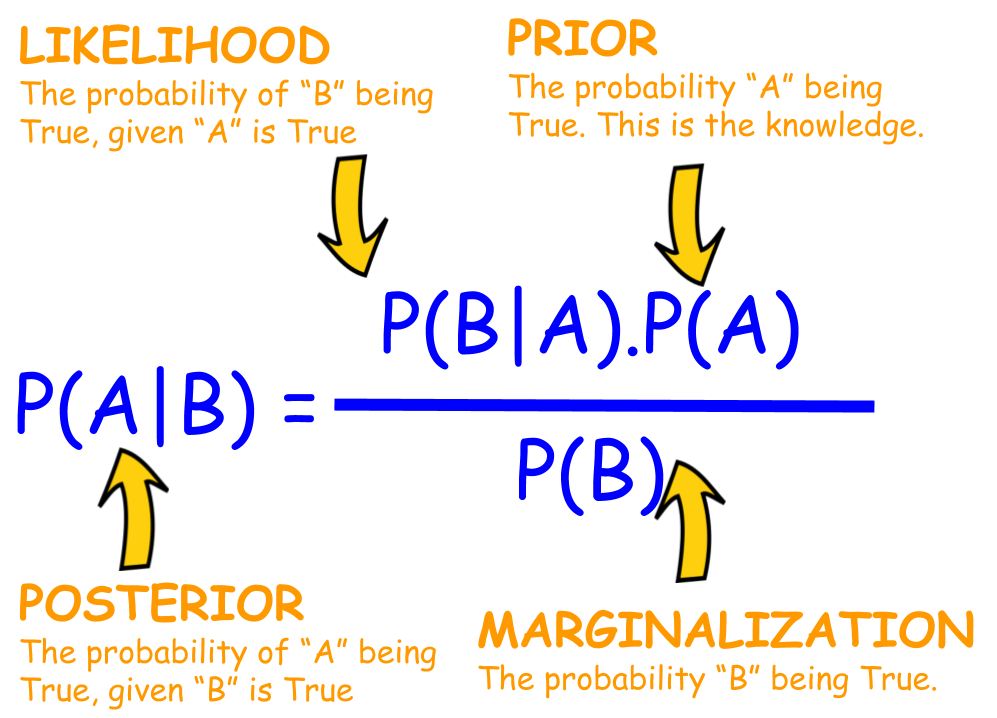
核心思想:贝叶斯公式,独立性假设 第一部分:贝叶斯公式 理论上,概率模型分类器是一个条件概率模型,这个我们已经并不陌生了,也就是要求出:
p ( y ∣ X ) p(y|X) p ( y ∣ X ) y y y X = X 1 , X 2 , ⋯ , X n X = X_1,X_2, \cdots,X_n X = X 1 , X 2 , ⋯ , X n n n n
p ( y ∣ X ) = p ( y ) ( p ( X ∣ y ) p ( X ) p(y|X) = \frac{p(y)(p(X|y)}{p(X)} p ( y ∣ X ) = p ( X ) p ( y ) ( p ( X ∣ y )
用简单的语言可以表示为:
举个例子,假如我们有一副扑克,我们想知道在给定它是一张带人的牌的情况下,我们抽的牌是king的概率。所以根据贝叶斯公式,我们知道
p( King ) 等于 4/52 因为在一副牌里面有 4 张Kingp( Face | King) 等于 1 因为所有的king都是属于带人的牌p( Face ) 等于 12/52 因为每一个花色都有 3 张带人的牌,总共有 12 张
接下来这个式子是我们会经常遇到的
p o s t e r i o r = p r i o r × l i k e l i h o o d e v i d e n c e posterior = \frac{prior \times likelihood}{evidence} p o s t e r i o r = e v i d e n c e p r i o r × l i k e l i h o o d
而实际中,我们只关心分式的分子部分, 因为分母不依赖于 y y y X X X 联合分布 模型。
p ( y , X = X 1 , X 2 , ⋯ , X n ) p(y, X = X_1,X_2, \cdots,X_n) p ( y , X = X 1 , X 2 , ⋯ , X n )
重复使用链式法则,可以将该式写成条件概率的形式,如下:p ( y , X 1 , X 2 , ⋯ , X n ) ∝ p ( y ) p ( X 1 , X 2 , ⋯ , X n ∣ y ) ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 , ⋯ , X n ∣ y , X 1 ) ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 ∣ y , X 1 ) p ( X 3 , ⋯ , X n ∣ y , X 1 , X 2 ) ⋯ ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 ∣ y , X 1 ) p ( X 3 ∣ y , X 1 , X 2 ) ⋯ p ( X n ∣ y , X 1 , X 2 , ⋯ , X n − 1 )
\begin{aligned}
p(y, X_1,X_2, \cdots,X_n) \\
&\propto p(y)p(X_1,X_2, \cdots,X_n|y) \\
&\propto p(y)p(X_1|y)p(X_2,\cdots,X_n|y,X_1) \\
&\propto p(y)p(X_1|y)p(X_2|y,X_1)p(X_3,\cdots,X_n|y,X_1,X_2) \\
&\cdots \\
&\propto p(y)p(X_1|y)p(X_2|y,X_1)p(X_3|y,X_1,X_2)\cdots p(X_n|y,X_1,X_2,\cdots,X_{n-1})
\end{aligned}
p ( y , X 1 , X 2 , ⋯ , X n ) ∝ p ( y ) p ( X 1 , X 2 , ⋯ , X n ∣ y ) ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 , ⋯ , X n ∣ y , X 1 ) ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 ∣ y , X 1 ) p ( X 3 , ⋯ , X n ∣ y , X 1 , X 2 ) ⋯ ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 ∣ y , X 1 ) p ( X 3 ∣ y , X 1 , X 2 ) ⋯ p ( X n ∣ y , X 1 , X 2 , ⋯ , X n − 1 )
第二部分:条件独立假设 从现在开始, “朴素”的条件独立假设开始发挥作用,什么叫条件独立 呢?当两个事件 A A A B B B Y Y Y A A A B B B A A A B B B Y Y Y A A A B B B B B B A A A
所以我们假设每个特征 X i X_i X i X j X_j X j j ≠ i j \neq i j = i
p ( X i ∣ y , X j ) = p ( X i ∣ y ) p(X_i|y,X_j) = p(X_i|y) p ( X i ∣ y , X j ) = p ( X i ∣ y )
对于 i ≠ j i \neq j i = j
p ( y ∣ X 1 , X 2 , ⋯ , X n ) ∝ p ( y , X 1 , X 2 , ⋯ , X n ) ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 ∣ y ) p ( X 3 ∣ y ) ⋯ ∝ p ( y ) ∏ i = 1 n p ( X i ∣ y )
\begin{aligned}
p(y|X_1,X_2, \cdots,X_n) \\
&\propto p(y, X_1,X_2, \cdots,X_n) \\
&\propto p(y)p(X_1|y)p(X_2|y)p(X_3|y) \cdots \\
&\propto p(y)\prod_{i=1}^{n}p(X_i|y)
\end{aligned}
p ( y ∣ X 1 , X 2 , ⋯ , X n ) ∝ p ( y , X 1 , X 2 , ⋯ , X n ) ∝ p ( y ) p ( X 1 ∣ y ) p ( X 2 ∣ y ) p ( X 3 ∣ y ) ⋯ ∝ p ( y ) i = 1 ∏ n p ( X i ∣ y )
所以这意味着,类变量 y y y
p ( y ∣ X 1 , X 2 , ⋯ , X n ) = 1 Z p ( y ) ∏ i = 1 n p ( X i ∣ y ) p(y|X_1,X_2, \cdots,X_n) = \frac{1}{Z}p(y)\prod_{i=1}^{n}p(X_i|y) p ( y ∣ X 1 , X 2 , ⋯ , X n ) = Z 1 p ( y ) i = 1 ∏ n p ( X i ∣ y )
其中 Z Z Z X 1 , X 2 , ⋯ , X n X_1,X_2, \cdots,X_n X 1 , X 2 , ⋯ , X n (prior) p ( y ) p(y) p ( y ) p ( X i ∣ y ) p(X_i|y) p ( X i ∣ y ) ∏ i = 1 n p ( X i ∣ y ) \prod_{i=1}^{n}p(X_i|y) ∏ i = 1 n p ( X i ∣ y ) (likelihood) 上述模型概率的稳定性得到很大提升。
第三部分:从概率模型中构造分类器 那么如何从朴素贝叶斯概率模型来构造一个分类器,这需要建立一个决策法则,一个很常见的法则就是选出最有可能的那个,就是最大后验概率(MAP) 决策准则,相应的分类器是如下定义的公式,这里我们假设 y y y K K K k k k
y ^ = arg max k ∈ [ 1 , ⋯ , K ] p ( y k ) ∏ i = 1 n p ( X i ∣ y k ) \hat y = \argmax\limits_{k \in [1,\cdots,K]}p(y_k)\prod_{i=1}^{n}p(X_i|y_k) y ^ = k ∈ [ 1 , ⋯ , K ] a r g m a x p ( y k ) i = 1 ∏ n p ( X i ∣ y k )
所有的模型参数都可以通过训练集的相关频率来估计,类的先验概率可以通过假设各类等概率来计算先 验 概 率 = 1 类 的 数 量 先验概率 = \frac{1} {类的数量} 先 验 概 率 = 类 的 数 量 1 A 类 先 验 概 率 = A 类 样 本 的 数 量 样 本 总 数 A类先验概率=\frac{A类样本的数量}{样本总数} A 类 先 验 概 率 = 样 本 总 数 A 类 样 本 的 数 量
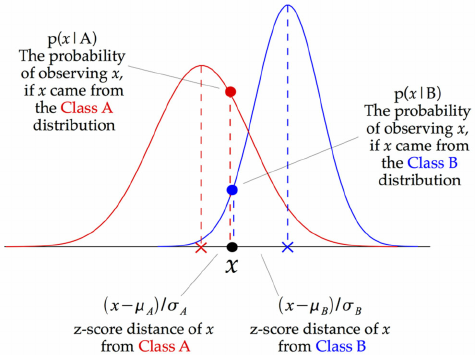
延伸:高斯朴素贝叶斯(GBN),线性判别分析(LDA),二次判别分析(QDA) 第一部分:高斯朴素贝叶斯(GBN)
如果要处理的是连续 数据,一种通常的假设是这些连续数值为高斯分布 。 例如,假设训练集中有一个连续特征 x x x x x x 均值 和方差 。
我们有:
p ( y = k ∣ X = x ) = π k f k ( x ) ∑ l = 1 k π l f l ( x ) p(y=k|X=x)=\frac{\pi_kf_k(x)}{\sum_{l=1}^{k}\pi_lf_l(x)} p ( y = k ∣ X = x ) = ∑ l = 1 k π l f l ( x ) π k f k ( x )
其中 π k \pi_k π k 先验概率 (prior),f k ( x ) f_k(x) f k ( x ) 似然函数 (likelihood)。
我们用一个特征 x = v x=v x = v
p ( x = v ∣ y = k ) = f k ( x ) = 1 2 π σ y 2 e x p ( − ( v − μ y ) 2 2 σ y 2 ) p(x = v|y=k) =f_k(x)= \frac{1}{\sqrt{2\pi\sigma_y^2}}exp\Big(-\frac{(v-\mu_y)^2}{2\sigma_y^2}\Big) p ( x = v ∣ y = k ) = f k ( x ) = 2 π σ y 2 1 e x p ( − 2 σ y 2 ( v − μ y ) 2 )
处理连续数值问题的另一种常用的技术是通过离散化连续数值的方法。通常,当训练样本数量较少 或者是精确的分布已知 时,通过概率分布的方法是一种更好的选择。在大量样本的情形下离散化的方法表现更优,因为大量的样本可以学习到数据的分布。由于朴素贝叶斯是一种典型的用到font color=red>大量样本的方法(越大计算量的模型可以产生越高的分类精确度 ),所以朴素贝叶斯方法都用到离散化方法,而不是概率分布估计的方法。
下面是GBN分类器的工作原理,在每一个数据点,在这一点和每个类平均(class-mean)的z-score都可以被计算出来。
如果一个给定的类和特征值在训练集中没有一起出现过,那么基于频率的估计下该概率将为0。这将是一个问题。因为与其他概率相乘时将会把其他概率的信息统统去除。所以常常要求要对每个小类样本的概率估计进行修正,以保证不会出现有为0的概率出现。
尽管实际上独立假设常常是不准确的,但朴素贝叶斯分类器的若干特性让其在实践中能够获取令人惊奇的效果。特别地,各类条件特征之间的解耦 (数学中解耦是指使含有多个变量的数学方程变成能够用单个变量表示的方程组,即变量不再同时共同直接影响一个方程的结果,从而简化分析计算)意味着每个特征的分布都可以独立地被当做一维分布来估计。
这样减轻了由于维数灾难 带来的阻碍,当样本的特征个数增加时就不需要使样本规模呈指数增长。然而朴素贝叶斯在大多数情况下不能对类概率做出非常准确的估计,但在许多应用中这一点并不要求。
例如,朴素贝叶斯分类器中,依据最大后验概率决策规则只要正确类的后验概率比其他类要高就可以得到正确的分类。所以不管概率估计轻度的甚至是严重的不精确都不影响正确的分类结果。在这种方式下,分类器可以有足够的鲁棒性去忽略朴素贝叶斯概率模型上存在的缺陷。
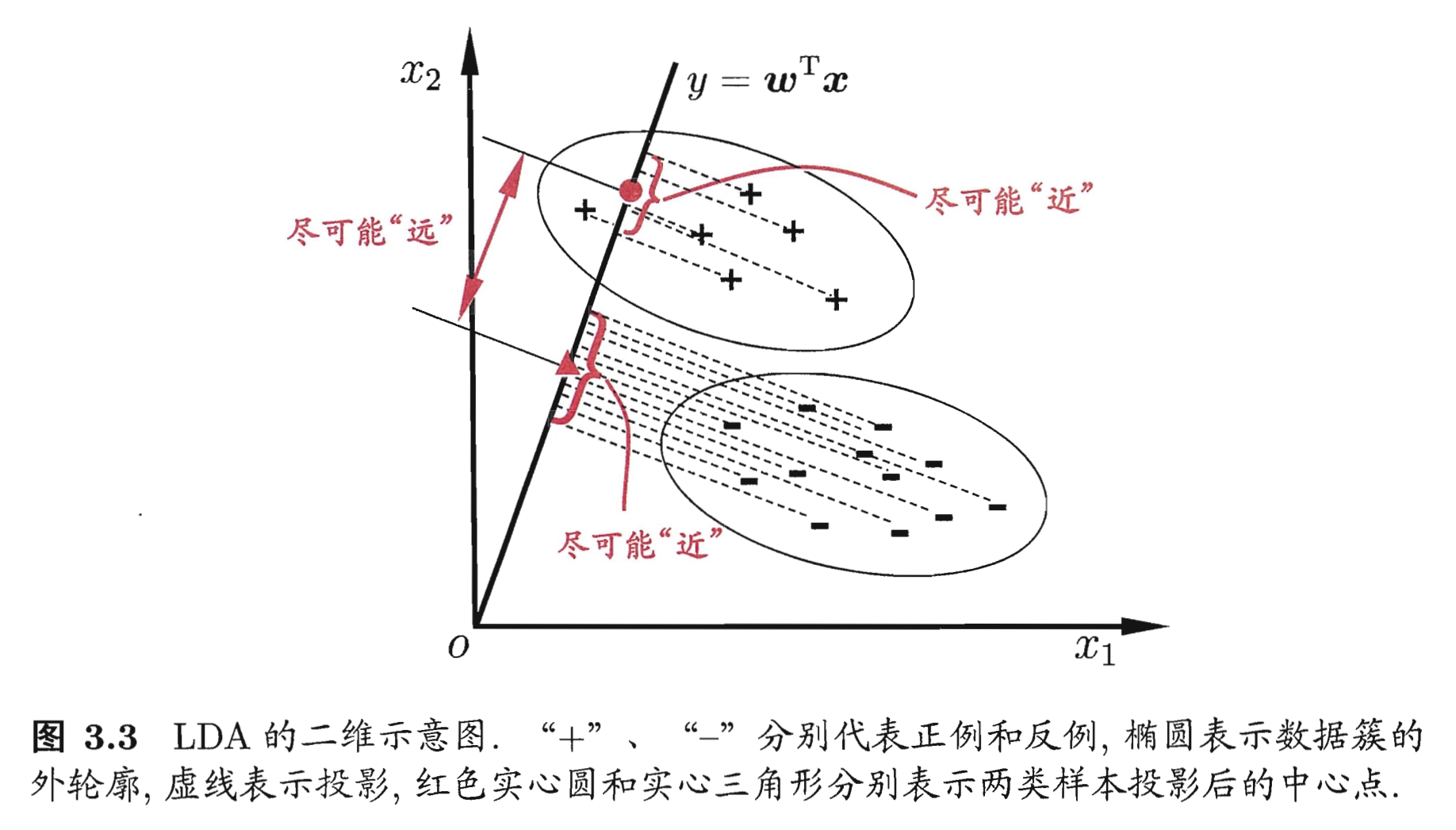
第二部分:线性判别分析(LDA) LDA核心思想 LDA作为一种有监督学习的降维、分类技术,可以在保持分类的前提下把数据投影到低维空间以降低计算复杂度。
LDA要求类间的方差最大,而类内的方差最小 ,以保证投影后同一分类数据集中,不同分类间数据距离尽可能大。
LDA数学推导 回顾一下之前说过的朴素贝叶斯方法,我们有:
P r i o r s = p ( y = k ) = π k Priors = p(y=k) = \pi_k P r i o r s = p ( y = k ) = π k L i k e l i h o o d = p ( X = x ∣ y = k ) = f k ( x ) = 1 ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 e x p ( − 1 2 ( x − μ k ) T Σ − 1 ( x − μ k ) ) Likelihood = p(X=x|y=k)=f_k(x)=\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}exp(-\frac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k)) L i k e l i h o o d = p ( X = x ∣ y = k ) = f k ( x ) = ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 1 e x p ( − 2 1 ( x − μ k ) T Σ − 1 ( x − μ k ) ) μ k \mu_k μ k k k k Σ \Sigma Σ (Common to all categories) 十分重要的假设,我们假设对每一类数据的协方差矩阵是相等的!
根据贝叶斯公式,我们计算出后验概率:
p ( y = k ∣ X = x ) = f k ( x ) π k P ( X = x ) p(y=k|X=x)=\frac{f_k(x)\pi_k}{P(X=x)} p ( y = k ∣ X = x ) = P ( X = x ) f k ( x ) π k
同样,分母可看做常数
p ( y = k ∣ X = x ) = C × f k ( x ) π k p(y=k|X=x)=C\times{f_k(x)\pi_k} p ( y = k ∣ X = x ) = C × f k ( x ) π k
展开可得
p ( y = k ∣ X = x ) = C π k ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 e x p ( − 1 2 ( x − μ k ) T Σ − 1 ( x − μ k ) ) p(y=k|X=x)=\frac{C\pi_k}{(2\pi)^{n/2}|\Sigma|^{1/2}}exp(-\frac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k)) p ( y = k ∣ X = x ) = ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 C π k e x p ( − 2 1 ( x − μ k ) T Σ − 1 ( x − μ k ) )
下面,我们把与 k k k C ′ C' C ′
p ( y = k ∣ X = x ) = C ′ π k e − 1 2 ( x − μ k ) T Σ − 1 ( x − μ k ) p(y=k|X=x)=C'\pi_ke^{-\frac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k)} p ( y = k ∣ X = x ) = C ′ π k e − 2 1 ( x − μ k ) T Σ − 1 ( x − μ k )
下面,对等式两边取对数
l o g p ( y = k ∣ X = x ) = l o g C ′ + l o g π k − 1 2 ( x − μ k ) T Σ − 1 ( x − μ k ) log\ p(y=k|X=x)=log\ C'+log\ \pi_k-\frac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k) l o g p ( y = k ∣ X = x ) = l o g C ′ + l o g π k − 2 1 ( x − μ k ) T Σ − 1 ( x − μ k )
注意,l o g C ′ log\ C' l o g C ′ k k k k k k
T a r g e t = l o g π k − 1 2 ( x − μ k ) T Σ − 1 ( x − μ k ) = l o g π k − 1 2 [ x T Σ − 1 x + μ k T Σ − 1 μ k ] + x T Σ − 1 μ k = C ′ ′ + l o g π k − 1 2 μ k T Σ − 1 μ k + x T Σ − 1 μ k
\begin{aligned}
Target &= log\ \pi_k-\frac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k) \\
&= log\ \pi_k-\frac{1}{2}[x^T\Sigma^{-1}x+\mu_k^T\Sigma^{-1}\mu_k]+x^T\Sigma^{-1}\mu_k \\
&= C''+log\ \pi_k - \frac{1}{2}\mu_k^T\Sigma^{-1}\mu_k+x^T\Sigma^{-1}\mu_k
\end{aligned}
T a r g e t = l o g π k − 2 1 ( x − μ k ) T Σ − 1 ( x − μ k ) = l o g π k − 2 1 [ x T Σ − 1 x + μ k T Σ − 1 μ k ] + x T Σ − 1 μ k = C ′ ′ + l o g π k − 2 1 μ k T Σ − 1 μ k + x T Σ − 1 μ k
我们定义我们要最大化的目标函数
δ k ( x ) = l o g π k − 1 2 μ k T Σ − 1 μ k + x T Σ − 1 μ k \delta_k(x) = log\ \pi_k-\frac{1}{2}\mu_k^T\Sigma^{-1}\mu_k+x^T\Sigma^{-1}\mu_k δ k ( x ) = l o g π k − 2 1 μ k T Σ − 1 μ k + x T Σ − 1 μ k
通过最大化 δ k ( x ) \delta_k(x) δ k ( x ) x x x
下面来看看LDA的决策边界
什么是决策边界?也就是一系列的数据点使得:
δ k ( x ) = δ l ( x ) \delta_k(x) = \delta_l(x) δ k ( x ) = δ l ( x )
l o g π k − 1 2 μ k T Σ − 1 μ k + x T Σ − 1 μ k = l o g π k − 1 2 μ l T Σ − 1 μ l + x T Σ − 1 μ l log\ \pi_k-\frac{1}{2}\mu_k^T\Sigma^{-1}\mu_k+x^T\Sigma^{-1}\mu_k = log\ \pi_k-\frac{1}{2}\mu_l^T\Sigma^{-1}\mu_l+x^T\Sigma^{-1}\mu_l l o g π k − 2 1 μ k T Σ − 1 μ k + x T Σ − 1 μ k = l o g π k − 2 1 μ l T Σ − 1 μ l + x T Σ − 1 μ l
那么接下来就到了参数估计的步骤了,记得之前我们已经说过 π k \pi_k π k μ k \mu_k μ k Σ \Sigma Σ
μ ^ k = 1 # ( i ; y i = k ) ∑ i ; y i = k x i \hat\mu_k = \frac{1}{\#(i;y_i=k)}\sum_{i;y_i=k}x_i μ ^ k = # ( i ; y i = k ) 1 i ; y i = k ∑ x i
σ ^ 2 = 1 n − K ∑ k = 1 K ∑ i ; y i = k ( x i − μ ^ k ) 2 \hat\sigma^2=\frac{1}{n-K}\sum_{k=1}^{K}\sum_{i;y_i=k}(x_i-\hat\mu_k)^2 σ ^ 2 = n − K 1 k = 1 ∑ K i ; y i = k ∑ ( x i − μ ^ k ) 2
这里的 ∑ i ; y i = k \sum_{i;y_i=k} ∑ i ; y i = k k k k
X = ( X 1 , X 2 , ⋯ , X n ) X = (X_1,X_2,\cdots,X_n) X = ( X 1 , X 2 , ⋯ , X n ) X ∼ N ( μ , Σ ) X \sim N(\mu,\Sigma) X ∼ N ( μ , Σ )
所以根据我们之前推出的 δ k ( x ) \delta_k(x) δ k ( x )
δ ^ k ( x ) = l o g π ^ k − 1 2 μ ^ k T Σ ^ − 1 μ ^ k + x T Σ ^ − 1 μ ^ k \hat\delta_k(x) = log\ \hat\pi_k-\frac{1}{2}\hat\mu_k^T\hat\Sigma^{-1}\hat\mu_k+x^T\hat\Sigma^{-1}\hat\mu_k δ ^ k ( x ) = l o g π ^ k − 2 1 μ ^ k T Σ ^ − 1 μ ^ k + x T Σ ^ − 1 μ ^ k
LDA与逻辑回归的关系
首先LR对于可以类别可以很准确分类的情况(well-seperated)很不稳定,而且很难处理多类分类问题,所以LDA作为一个生成模型,针对那些 f ( X ∣ y ) f(X|y) f ( X ∣ y )
对于LR,我们有p ( y = 1 ∣ X ) = p 1 = 1 1 + e − θ T x p(y=1|X)=p_1=\frac{1}{1+e^{-\theta^Tx}} p ( y = 1 ∣ X ) = p 1 = 1 + e − θ T x 1 l o g ( p 1 1 − p 1 ) = θ T x log(\frac{p_1}{1-p_1})=\theta^Tx l o g ( 1 − p 1 p 1 ) = θ T x l o g ( p 1 1 − p 1 ) = w T x log(\frac{p_1}{1-p_1})=w^Tx l o g ( 1 − p 1 p 1 ) = w T x w w w μ k \mu_k μ k σ k \sigma_k σ k
第三部分:二次判别分析(QDA) 至于QDA,它跟LDA的区别在于我们去掉了之前重要的假设,也就是在QDA中,我们要对每个类 k k k μ ^ k \hat\mu_k μ ^ k Σ ^ k \hat\Sigma_k Σ ^ k
根据之前推导的 δ k ( x ) \delta_k(x) δ k ( x )
δ k ( x ) = l o g π k − 1 2 μ k T Σ − 1 μ k + x T Σ − 1 μ k − 1 2 x T Σ k − 1 x − 1 2 l o g ∣ Σ k ∣ \delta_k(x) = log\ \pi_k-\frac{1}{2}\mu_k^T\Sigma^{-1}\mu_k+x^T\Sigma^{-1}\mu_k - \frac{1}{2}x^T\Sigma_k^{-1}x-\frac{1}{2}log\ |\Sigma_k| δ k ( x ) = l o g π k − 2 1 μ k T Σ − 1 μ k + x T Σ − 1 μ k − 2 1 x T Σ k − 1 x − 2 1 l o g ∣ Σ k ∣
可以看出 δ k ( x ) \delta_k(x) δ k ( x ) x x x 二次函数
来看一下LDA和QDA的决策边界的对比
当我们分别去求 Σ ^ k \hat\Sigma_k Σ ^ k
实际应用和代码展示 朴素贝叶斯方法相关面经和其他资料 小结 朴素贝叶斯算法的基本思想是建立特征 X X X y y y p ( X , y ) p(X,y) p ( X , y ) 贝叶斯定理 求出所有可能的输出 p(X|y) ,取其中最大的作为预测结果。其优点是模型简单,效率高,在很多领域有广泛的使用。朴素贝叶斯、LDA/QDA都属于生成模型,收敛速度将快于判别模型(如逻辑回归)。
支持向量机
什么是支持向量机? 支持向量机(Support Vector Machine, SVM) 是一种二类分类器。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机 ;支持向量机还包括核技巧 ,这使其成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化 ,可形式化为一个求解凸二次规划(convex quadratic programming)的问题,也等价于正则化的**合页损失函数(Hinge Loss)**的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化算法。
支持向量机包含构建由简至繁的模型:线性可分支持向量机、线性支持向量机以及非线性支持向量机。当数据线性可分时,通过硬间隔最大化(hard margin maximization),学习一个线性的分类器;当数据近似线性可分时,通过软间隔最大化(soft margin maximization),也学习一个线性的分类器,也就是线性支持向量机,也叫做软间隔支持向量机;当数据线性不可分时,通过使用核技巧(kernel trick)以及软间隔最大化,学习非线性支持向量机。
核心思想:硬(软)间隔最大化、合页损失函数、决策边界、核函数 第一部分:硬(软)间隔最大化 首先,考虑一个二分类问题,我们假设给定一个特征空间上的训练数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T = \{ (x_1,y1), (x_2,y_2), \cdots, (x_N,y_N)\} T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) }
其中,x i = R n , y i = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N x_i = R^n, y_i = \{+1,-1\}, i = 1,2,\cdots,N x i = R n , y i = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N x i x_i x i i i i y i y_i y i x i x_i x i 分离超平面 对应方程 w ⋅ x + b = 0 w\cdot x+b = 0 w ⋅ x + b = 0 w w w b b b y i = + 1 y_i = +1 y i = + 1 y i = − 1 y_i = -1 y i = − 1
一般来说,在训练集线性可分,存在无穷个分离超平面进行分类,感知机利用误分类最小的策略,求分离超平面,这时解有无穷多个。线性可分支持向量机可以利用间隔最大化求最优分离超平面,这时,解是唯一的!
下面来说说间隔最大化 ,最直观的解释是:对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类。也就是说,不仅将正负实例点分开,而且对最难分的实例点(离超平面最近的点)也有足够大的确信度将它们分开。这样的超平面应该对未知的新实例有很好的分类预测能力。
具体来说,这个问题可以表示为下面的约束最优化问题:
max w , b γ \max_{w,b} \quad \gamma w , b max γ
s . t . y i ( w ∣ ∣ w ∣ ∣ ⋅ x i + b ∣ ∣ w ∣ ∣ ) ≥ γ , i = 1 , 2 , ⋯ , N s.t. \quad y_i \Big(\frac{w}{||w||} \cdot x_i + \frac{b}{||w||}\Big)\geq\gamma, \quad i=1,2,\cdots,N s . t . y i ( ∣ ∣ w ∣ ∣ w ⋅ x i + ∣ ∣ w ∣ ∣ b ) ≥ γ , i = 1 , 2 , ⋯ , N
我们希望最大化超平面 ( w , b ) (w,b) ( w , b ) γ \gamma γ γ \gamma γ
注意到函数间隔的取值并不影响最优化的解。事实上,假设将 w w w b b b γ = 1 \gamma = 1 γ = 1 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣ ∣ w ∣ ∣ 1 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 2 1 ∣ ∣ w ∣ ∣ 2
十分重要!
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 \min_{w,b} \quad \frac{1}{2}||w||^2 w , b min 2 1 ∣ ∣ w ∣ ∣ 2
s . t . y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , 2 , ⋯ , N s.t. \quad y_i(w\cdot x_i+b) - 1 \geq 0, \quad i=1,2,\cdots,N s . t . y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , 2 , ⋯ , N
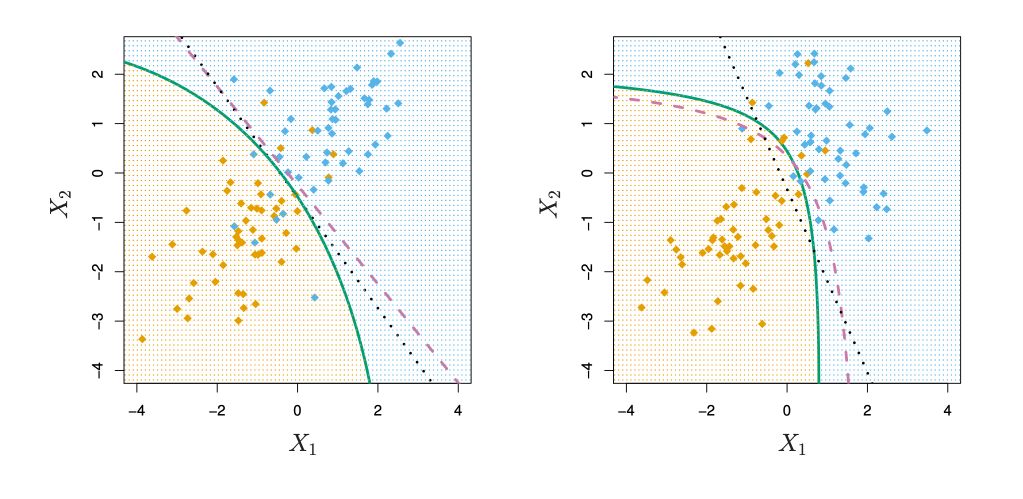
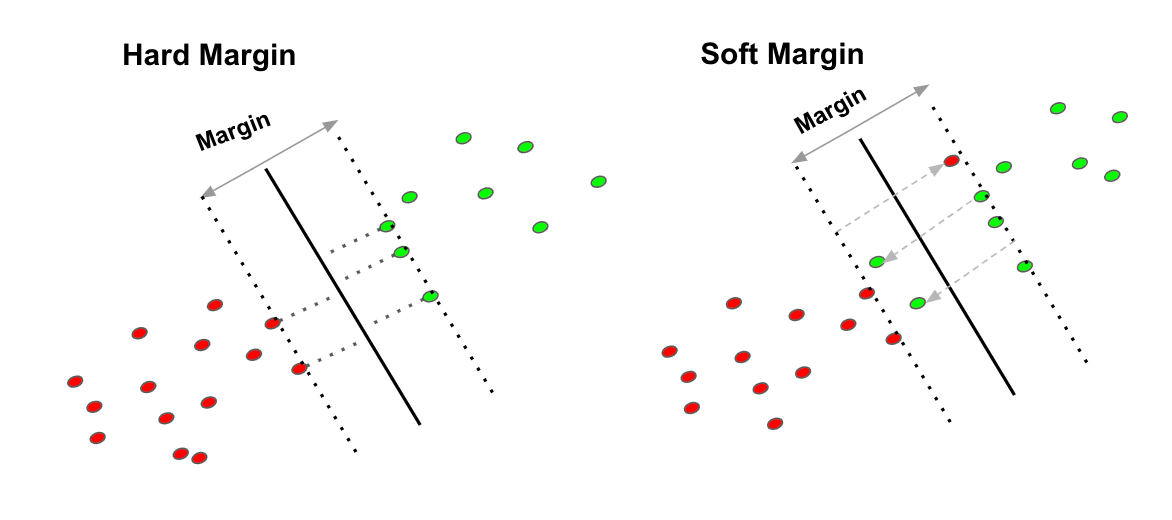
下面来说一下什么是硬(软)间隔,我们知道SVM本质就是最大化margin,但是面对如下图所示的一些overlapping或者说是异常点,我们很难找到一个合适的决策边界来分类,但是我们如果绝对遵从正确分类的话,会造成下图右边的图片所示的情况,但是这明显有悖于我们全局边际最大化的初衷,自然我们要做些取舍,我们要允许错误分类 (misclassification)从而保证全局最优化。
再从数学层面上解释为什么要引入软间隔最大化,是因为在面对线性不可分数据时,上述的不等式约束 y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , 2 , ⋯ , N \quad y_i(w\cdot x_i+b) - 1 \geq 0, \quad i=1,2,\cdots,N y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , 2 , ⋯ , N
那为了解决这个问题,我们对每个样本点 ( x i , y i ) (x_i,y_i) ( x i , y i ) 松弛变量 ξ i ≥ 0 \xi_i \geq 0 ξ i ≥ 0
y i ( w ⋅ x i + b ) ≥ 1 − ξ i \quad y_i(w\cdot x_i+b) \geq 1 - \xi_i y i ( w ⋅ x i + b ) ≥ 1 − ξ i
同时,对每个 ξ i \xi_i ξ i ξ i \xi_i ξ i 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 2 1 ∣ ∣ w ∣ ∣ 2
1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \frac{1}{2}||w||^2+C\sum_{i=1}^{N}\xi_i 2 1 ∣ ∣ w ∣ ∣ 2 + C i = 1 ∑ N ξ i
这里的 C > 0 C>0 C > 0 C C C 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \frac{1}{2}||w||^2+C\sum_{i=1}^{N}\xi_i 2 1 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i 使得 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 2 1 ∣ ∣ w ∣ ∣ 2 。
所以我们有
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \min_{w,b,\xi} \quad \frac{1}{2}||w||^2 + C\sum_{i=1}^{N}\xi_i w , b , ξ min 2 1 ∣ ∣ w ∣ ∣ 2 + C i = 1 ∑ N ξ i
s . t . y i ( w ⋅ x i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , N s.t. \quad \quad y_i(w\cdot x_i+b) \geq 1 - \xi_i, \quad i=1,2,\cdots,N s . t . y i ( w ⋅ x i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , N
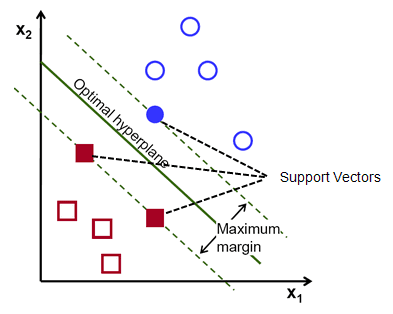
第二部分:支持向量和间隔边界 支持向量 在线性可分的情况下,训练集的样本点钟与分离超平面距离最近的样本点的实例称为支持向量(support vector)。支持向量是使约束条件等式成立的点,即:
y i ( w ⋅ x i + b ) − 1 = 0 , i = 1 , 2 , ⋯ , N \quad y_i(w\cdot x_i+b) - 1 = 0, \quad i=1,2,\cdots,N y i ( w ⋅ x i + b ) − 1 = 0 , i = 1 , 2 , ⋯ , N
对 y i = + 1 y_i = +1 y i = + 1
H 1 = w ⋅ x + b = 1 H_1 = w\cdot x+b=1 H 1 = w ⋅ x + b = 1
上,对 y i = + 1 y_i = +1 y i = + 1
H 1 = w ⋅ x + b = − 1 H_1 = w\cdot x+b=-1 H 1 = w ⋅ x + b = − 1
上。如下图所示,在 H 1 H_1 H 1 H 2 H_2 H 2
间隔边界 注意到 H 1 H_1 H 1 H 2 H_2 H 2 H 1 H_1 H 1 H 2 H_2 H 2 间隔(margin) 。间隔依赖于分离超平面的法向量 w w w 2 ∣ ∣ w ∣ ∣ \frac{2}{||w||} ∣ ∣ w ∣ ∣ 2 H 1 H_1 H 1 H 2 H_2 H 2 间隔边界 。
再决定分离超平面时只有支持向量起作用,而其他实例点并不起作用。如果移动支持向量将改变所求的解;但是如果在间隔边界意外移动其他实例点,甚至去掉这些点,则解不会改变。也就是说解只跟支持向量相关 !
由于支持向量在确定分离超平面起着决定性作用,所以支持向量机就由此而来。一般来说,支持向量的个数相对较少,所以支持向量机由很少的“重要”样本确定。
第三部分:对偶算法 这一部分是SVM最核心也是最理论的部分,所以分成几小部分展开。
无约束最小化 我们之前所讨论的最小化问题是带有边界条件的,也就是我们要满足数据集里所有的点到分离超平面的距离都要超过 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣ ∣ w ∣ ∣ 1
定理:令 f : Ω → R f: \Omega \rarr \mathbb{R} f : Ω → R x ∗ x^* x ∗ x ∗ x^* x ∗ ∇ f ( x ∗ ) = 0 \nabla f(x^*) = 0 ∇ f ( x ∗ ) = 0 ∇ 2 f ( x ∗ ) \nabla^2 f(x^*) ∇ 2 f ( x ∗ ) x ∗ x^* x ∗ 证明 ,第11页)
敲黑板!!!
也就是说,如果 x ∗ x^* x ∗
f f f x ∗ x^* x ∗ ∇ f ( x ∗ ) = 0 \nabla f(x^*) = 0 ∇ f ( x ∗ ) = 0 f f f x ∗ x^* x ∗ z T ( ( ∇ 2 f ( x ∗ ) ) z > 0 , ∀ z ∈ R n z^T((\nabla^2 f(x^*))z>0, \forall z \in \mathbb{R}^n z T ( ( ∇ 2 f ( x ∗ ) ) z > 0 , ∀ z ∈ R n ∇ 2 f ( x ) = ( ∂ 2 f ∂ x 1 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ⋯ ∂ 2 f ∂ x n 2 ) \nabla^2f(\mathbf x) = \begin{pmatrix}\frac{\partial^2f}{\partial x^2_1 } & \cdots & \frac{\partial^2f}{\partial x_1 \partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial^2f}{\partial x_n \partial x_1} & \cdots & \frac{\partial^2f}{\partial x^2_n}\end{pmatrix} ∇ 2 f ( x ) = ⎝ ⎜ ⎜ ⎛ ∂ x 1 2 ∂ 2 f ⋮ ∂ x n ∂ x 1 ∂ 2 f ⋯ ⋱ ⋯ ∂ x 1 ∂ x n ∂ 2 f ⋮ ∂ x n 2 ∂ 2 f ⎠ ⎟ ⎟ ⎞ x ∗ x^* x ∗
这里主要说一下海森矩阵
海森矩阵一般简写为 H H H ∇ 2 f ( x ∗ ) \nabla^2 f(x^*) ∇ 2 f ( x ∗ ) ∇ 2 \nabla^2 ∇ 2
我们把数据带进去是可以算出海森矩阵的,海森矩阵是一个关于一个标量函数的二阶偏导所构成的对称方阵 ,它描述了多变量函数的局部曲率。
下面说一下什么是正定
我们需要判断海森矩阵在 x ∗ x^* x ∗
定义:如果对于所有 x ∈ R n x \in \mathbb{R}^n x ∈ R n x T A x > 0 x^TAx>0 x T A x > 0 A A A A = A T A = A^T A = A T
在这里我们把 x x x z z z A A A ∇ 2 f ( x ∗ ) \nabla^2 f(x^*) ∇ 2 f ( x ∗ )
z T ( ( ∇ 2 f ( x ∗ ) ) z > 0 , ∀ z ∈ R n z^T((\nabla^2 f(x^*))z>0, \forall z \in \mathbb{R}^n z T ( ( ∇ 2 f ( x ∗ ) ) z > 0 , ∀ z ∈ R n
但是明显我们不能对于所有的 z z z
A A A A A A A A A 存在一个非奇异(可逆)矩阵 B B B A = B T B A = B^TB A = B T B
具体如何判断请看这里 !
如果我们能够找到所有满足以上两个条件的 X X X
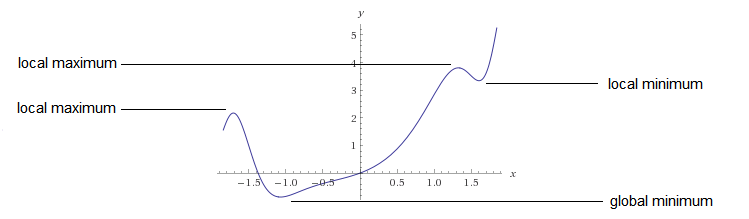
那么如何找到全局最小值呢?
找到所有的局部最小值
取最小的局部最小值
另一种方法是判定函数是不是凸函数,如果是的话,那么局部最小值就是全局最小值!如果有兴趣请看这里(强烈建议 )
对偶问题的引入:拉格朗日乘子 那么终于来到了我们的主角:对偶问题
在数学优化理论中,对偶性 意味着可以从原始问题或对偶问题(对偶性原理 )这两个角度来看优化问题。对偶问题的解决方案为原始(最小化)问题的解决方案提供了下限。(维基百科 )
什么是下限?
给个例子吧,加入我们有
S = { 2 , 4 , 8 , 12 } S = \{2,4,8,12\} S = { 2 , 4 , 8 , 1 2 }
因为1小于或等于2、4、8和12,所以我可以说1是S的下限。
例如,-3也是如此
即使它在S中,我们也可以称2为S的下限。
而且,因为2比任何其他下限大,所以我们可以给它起一个特殊的名字,我们称它为最大下限 。
为什么要关心对偶呢?
是因为有时候解决对偶问题比解决原问题更加简单,如果你有一个最小化的问题,那么你也可以把他看做一个最大化问题。也就是当你在找这个问题的最小值时,其实这就是一个最小化问题的解的下界 。
那么对偶的重要性体现在哪?
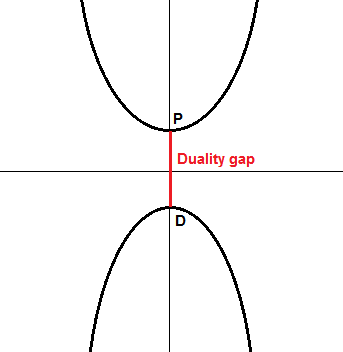
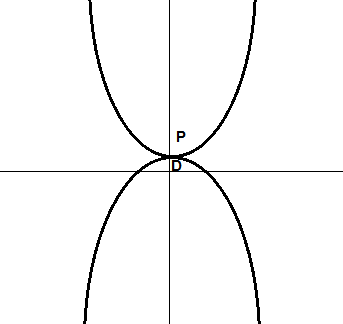
左边图中,我们可以看到在原问题中,我们要去对顶上的函数来最小化,它的最小值在 P P P D D D D D D P − D P-D P − D 对偶间隙(duality gap) ,在这里,P − D > 0 P-D>0 P − D > 0 弱对偶 ,而右边的图展示的是强对偶 ,也就是 P − D = 0 P-D=0 P − D = 0
之前介绍了无限制最优化问题的解决方法,下面说一下有限制条件的最优化问题解决方法。
一个最优化问题可以简单写成:
minimize x f ( x ) subject to g i ( x ) = 0 , i = 1 , … , p h i ( x ) ≤ 0 , i = 1 , … , m \begin{aligned}&{\underset {x}{\operatorname {minimize} }}&&f(x)\\&\operatorname {subject\;to} &&g_{i}(x)=0,\quad i=1,\dots ,p\\&&&h_{i}(x)\leq 0,\quad i=1,\dots ,m\end{aligned} x m i n i m i z e s u b j e c t t o f ( x ) g i ( x ) = 0 , i = 1 , … , p h i ( x ) ≤ 0 , i = 1 , … , m
这里,f f f x x x x ∗ x^* x ∗ f f f
这里有 p p p g i g_i g i m m m h i h_i h i
所以如何解决这种问题呢?
我们引入了拉格朗日乘子(Lagrange Multipliers) ,下面是维基百科中的英文解释。
In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints. (Wikipedia )
拉格朗日告诉我们如果要去寻找一个约束方程的最小值,那么我们需要去寻找使得 ∇ f ( x , y ) = λ ∇ g ( x , y ) \nabla f(x,y) = \lambda \nabla g(x,y) ∇ f ( x , y ) = λ ∇ g ( x , y )
那么 λ \lambda λ 拉格朗日乘子 。注意到这个公式不要求梯度是有相同的方向的,因为 λ \lambda λ
我们定义:
L ( x , λ , η ) = f ( x ) + ∑ i = 1 m λ i g i ( x ) + ∑ i = 1 p η i h i ( x ) L(x,\lambda, \eta) = f(x)+\sum_{i=1}^{m}\lambda_i g_i(x) + \sum_{i=1}^{p} \eta_ih_i(x) L ( x , λ , η ) = f ( x ) + i = 1 ∑ m λ i g i ( x ) + i = 1 ∑ p η i h i ( x )
那么原问题等价于无约束形式:
min x max λ , η L ( x , λ , η ) s . t . λ i ≥ 0 \min_{x}\max_{\lambda,\eta}L(x,\lambda,\eta)\quad s.t. \quad \lambda_i \geq 0 x min λ , η max L ( x , λ , η ) s . t . λ i ≥ 0
这是因为当满足原问题的不等式约束时, λ i = 0 \lambda_i = 0 λ i = 0
这个问题的对偶形式:
max λ , η min x L ( x , λ , η ) s . t . λ i ≥ 0 \max_{\lambda,\eta}\min_{x}L(x,\lambda,\eta)\quad s.t. \quad \lambda_i \geq 0 λ , η max x min L ( x , λ , η ) s . t . λ i ≥ 0
所以对偶问题是关于 λ , η \lambda, \eta λ , η
由于:
max λ i , η j min x L ( x , λ i , η j ) ≤ min x max λ i , η j L ( x , λ i , η j ) \max_{\lambda_i,\eta_j}\min_{x}L(x,\lambda_i,\eta_j) \leq \min_{x}\max_{\lambda_i,\eta_j}L(x,\lambda_i,\eta_j) λ i , η j max x min L ( x , λ i , η j ) ≤ x min λ i , η j max L ( x , λ i , η j )
证:显然有min x L ≤ L ≤ max λ , η \min_{x}L \leq L \leq \max_{\lambda,\eta} x min L ≤ L ≤ λ , η max max λ , η min x L ≤ L \max_{\lambda, \eta} \min_{x}L \leq L λ , η max x min L ≤ L min x max λ , η L ≥ L \min_{x} \max_{\lambda, \eta} L \geq L x min λ , η max L ≥ L
Wolfe dual Lagrangian function 下面我们对原问题进行对偶转化,看看是否能在原有的拉格朗日方程的基础上减少一些变量。
还记得朗格朗日方程是:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 m α i [ y i ( w ⋅ x i + b ) − 1 ] L(w,b,\alpha) = \frac{1}{2}||w||^2-\sum_{i=1}^{m}\alpha_i[y_i(w \cdot x_i + b) -1] L ( w , b , α ) = 2 1 ∣ ∣ w ∣ ∣ 2 − i = 1 ∑ m α i [ y i ( w ⋅ x i + b ) − 1 ]
拉格朗日原问题是:
min w , b max α L ( w , b , α ) \min_{w,b} \max_{\alpha} L(w,b,\alpha) w , b min α max L ( w , b , α ) s u b j e c t t o a i ≥ 0 , i = 1 , ⋯ , m subject \ to \quad a_i \geq 0, \ i = 1, \cdots, m s u b j e c t t o a i ≥ 0 , i = 1 , ⋯ , m
对于求解最小值问题,我们对 L L L w w w b b b
∇ w L = w − ∑ i = 1 m α i y i x i = 0 ∂ L ∂ b = − ∑ i = 1 m α i y i = 0 \begin{aligned}
\nabla_wL &= w - \sum_{i=1}^{m}\alpha_iy_ix_i=0 \\
\frac{\partial L}{\partial b} &= -\sum_{i=1}^{m}\alpha_iy_i = 0
\end{aligned} ∇ w L ∂ b ∂ L = w − i = 1 ∑ m α i y i x i = 0 = − i = 1 ∑ m α i y i = 0
通过第一个等式,我们有
w = ∑ i = 1 m α i y i x i w = \sum_{i=1}^{m}\alpha_iy_ix_i w = i = 1 ∑ m α i y i x i
我们把上式带入 L L L
W ( α , b ) = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j − b ∑ i = 1 m α i y i W(\alpha,b) = \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \cdot x_j - b\sum_{i=1}^{m}\alpha_iy_i W ( α , b ) = i = 1 ∑ m α i − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i ⋅ x j − b i = 1 ∑ m α i y i
到此,我们已经把 w w w ∂ L ∂ b = 0 \frac{\partial L}{\partial b}=0 ∂ b ∂ L = 0
W ( α ) = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j W(\alpha) = \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \cdot x_j W ( α ) = i = 1 ∑ m α i − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i ⋅ x j
上式也称为 Wolfe dual Lagrangian function
问题也被转化为了 wolfe 对偶问题:
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j \max_\alpha \ \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \cdot x_j α max i = 1 ∑ m α i − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i ⋅ x j
s u b j e c t t o α i ≥ 0 , f o r a n y i = 1 , ⋯ , m subject \ to \quad \alpha_i \geq 0, \ for \ any \ i = 1, \cdots , m s u b j e c t t o α i ≥ 0 , f o r a n y i = 1 , ⋯ , m
∑ i = 1 m α i y i = 0 \sum_{i=1}^{m}\alpha_iy_i=0 i = 1 ∑ m α i y i = 0
我们可以看到,这样一来我们的目标方程 W W W
KKT条件 因为我们解决的问题包含不等式约束条件,那么这里有个额外的条件我们不得不满足:解必须满足 Karsuh-Kuhn-Tucker (KKT) 条件 。
简单说,如果一个解满足KKT条件,那么可以保证它就是一个最优解。
KKT条件是:
Stationary condition:∇ w L = w − ∑ i = 1 m α i y i x i = 0 ∂ L ∂ b = − ∑ i = 1 m α i y i = 0 \begin{aligned}
\nabla_wL &= w - \sum_{i=1}^{m}\alpha_iy_ix_i=0 \\
\frac{\partial L}{\partial b} &= -\sum_{i=1}^{m}\alpha_iy_i = 0
\end{aligned} ∇ w L ∂ b ∂ L = w − i = 1 ∑ m α i y i x i = 0 = − i = 1 ∑ m α i y i = 0
Primal feasibility condition:y i ( w ⋅ x i + b ) − 1 ≥ 0 f o r a l l i = 1 , ⋯ , m y_i(w \cdot x_i + b) - 1 \geq 0 \quad for \ all \ i = 1, \cdots,m y i ( w ⋅ x i + b ) − 1 ≥ 0 f o r a l l i = 1 , ⋯ , m
Dual feasibility condition:α i ≥ 0 f o r a l l i = 1 , ⋯ , m \alpha_i \geq 0 \quad for \ all \ i = 1, \cdots,m α i ≥ 0 f o r a l l i = 1 , ⋯ , m
Complementary slackness condition:α i [ y i ( w ⋅ x i + b ) − 1 ] = 0 f o r a l l i = 1 , ⋯ , m \alpha_i [y_i(w \cdot x_i + b) - 1 ]=0 \quad for \ all \ i = 1, \cdots,m α i [ y i ( w ⋅ x i + b ) − 1 ] = 0 f o r a l l i = 1 , ⋯ , m α i = 0 \alpha_i=0 α i = 0 y i ( w ⋅ x i + b ) − 1 = 0 y_i(w \cdot x_i + b) - 1=0 y i ( w ⋅ x i + b ) − 1 = 0
所以接下来一旦我们有了拉格朗日乘子,就可以计算 w = ∑ i = 1 m α i y i x i w = \sum_{i=1}^{m}\alpha_iy_ix_i w = ∑ i = 1 m α i y i x i b = y i − w ⋅ x i b = y_i - w \cdot x_i b = y i − w ⋅ x i b b b x i x_i x i
b = 1 S ∑ i = 1 S ( y i − w ⋅ x i ) b = \frac{1}{S}\sum_{i=1}^{S}(y_i-w \cdot x_i) b = S 1 i = 1 ∑ S ( y i − w ⋅ x i )
其中 S S S
软间隔条件下的对偶问题 之前说过了硬软间隔最大化的目的以及他们的区别,简而言之,硬间隔最大化面对异常值特别敏感,很容易造成过拟合,而软间隔基于硬间隔加入了松弛变量,从而容许分类器有错误分类的情况,从而对全局的分类效果更佳。
既然说到了松弛变量 ζ \zeta ζ
y i ( w ⋅ x i + b ) ≥ 1 y_i(w \cdot x_i + b) \geq 1 y i ( w ⋅ x i + b ) ≥ 1
变成了:
y i ( w ⋅ x i + b ) ≥ 1 − ζ i y_i(w \cdot x_i + b) \geq 1-\zeta_i y i ( w ⋅ x i + b ) ≥ 1 − ζ i
但如果 ζ i \zeta_i ζ i ζ i \zeta_i ζ i
min w , b , ζ 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m ζ i \min_{w,b,\zeta} \frac{1}{2}||w||^2+\sum_{i=1}^{m}\zeta_i w , b , ζ min 2 1 ∣ ∣ w ∣ ∣ 2 + i = 1 ∑ m ζ i
s u b j e c t t o y i ( w ⋅ x i + b ) ≥ 1 − ζ i f o r a n y i = 1 , ⋯ , m subject \ to \quad y_i(w \cdot x_i + b) \geq 1 - \zeta_i \quad for \ any \ i = 1, \cdots , m s u b j e c t t o y i ( w ⋅ x i + b ) ≥ 1 − ζ i f o r a n y i = 1 , ⋯ , m
这里,我们把所有的 ζ i \zeta_i ζ i
还有个问题就是,我们要保证 ζ i ≥ 0 \zeta_i \geq 0 ζ i ≥ 0 C C C C C C ζ \zeta ζ
最终,对于软间隔情况,我们有:
min w , b , ζ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ζ i \min_{w,b,\zeta} \frac{1}{2}||w||^2+C\sum_{i=1}^{m}\zeta_i w , b , ζ min 2 1 ∣ ∣ w ∣ ∣ 2 + C i = 1 ∑ m ζ i
s u b j e c t t o y i ( w ⋅ x i + b ) ≥ 1 − ζ i ζ ≥ 0 f o r a n y i = 1 , ⋯ , m subject \ to \quad y_i(w \cdot x_i + b) \geq 1 - \zeta_i \quad \zeta \geq 0 \quad for \ any \ i = 1, \cdots , m s u b j e c t t o y i ( w ⋅ x i + b ) ≥ 1 − ζ i ζ ≥ 0 f o r a n y i = 1 , ⋯ , m
同理,我们对于软间隔情况有类似的对偶转换:
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j \max_\alpha \ \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \cdot x_j α max i = 1 ∑ m α i − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i ⋅ x j
s u b j e c t t o 0 ≤ α i ≤ C , f o r a n y i = 1 , ⋯ , m subject \ to \quad 0 \leq \alpha_i \leq C, \ for \ any \ i = 1, \cdots , m s u b j e c t t o 0 ≤ α i ≤ C , f o r a n y i = 1 , ⋯ , m
∑ i = 1 m α i y i = 0 \sum_{i=1}^{m}\alpha_iy_i=0 i = 1 ∑ m α i y i = 0
由于损失函数加入了 C ∑ i = 1 m ζ i C\sum_{i=1}^{m}\zeta_i C ∑ i = 1 m ζ i α i \alpha_i α i C C C C C C
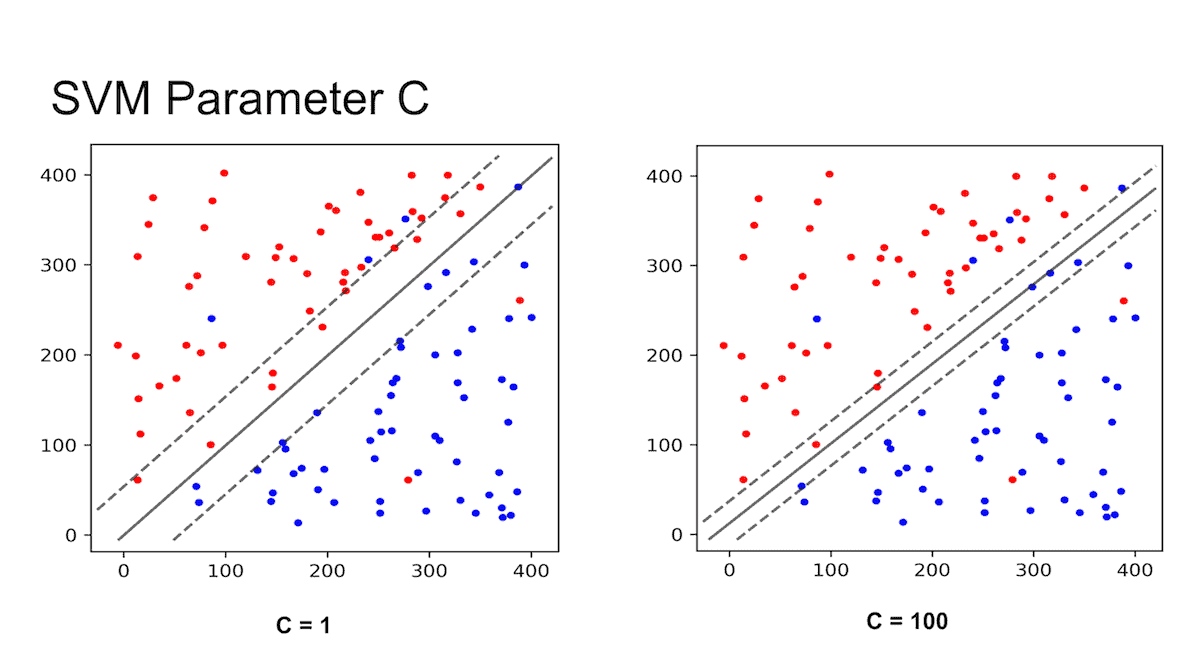
重点!!!
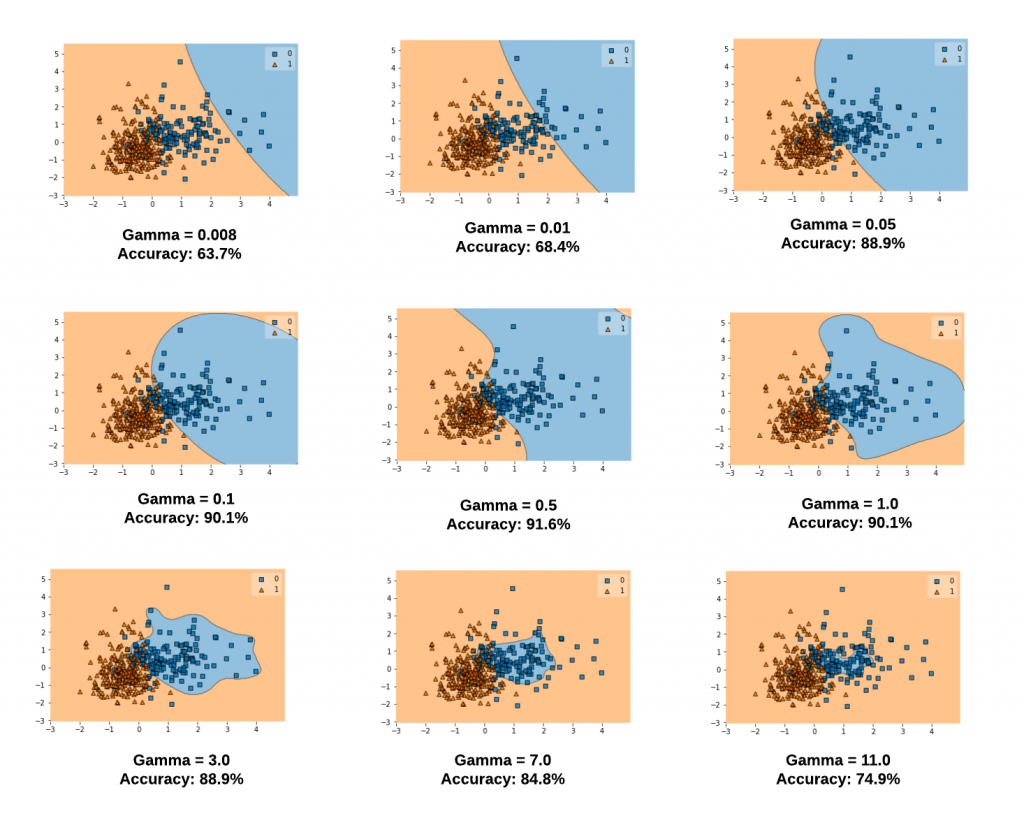
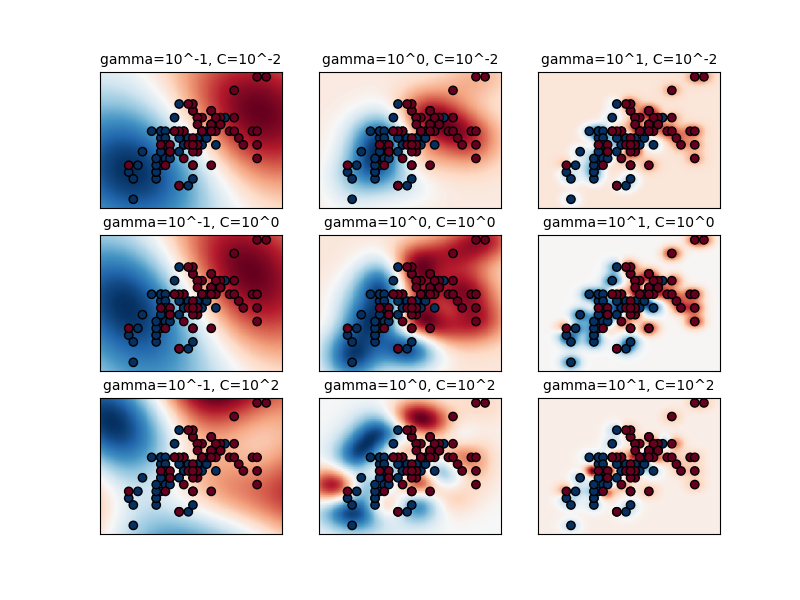
当 C C C
当 C C C
关键就在于如何选择一个最适合的 C C C
那么如何选择 C C C grid search 和 cross validation 。
延伸 2-Norm soft margin
min w , b , ζ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ζ i 2 \min_{w,b,\zeta} \frac{1}{2}||w||^2+C\sum_{i=1}^{m}\zeta_i^2 w , b , ζ min 2 1 ∣ ∣ w ∣ ∣ 2 + C i = 1 ∑ m ζ i 2
s u b j e c t t o y i ( w ⋅ x i + b ) ≥ 1 − ζ i ζ ≥ 0 f o r a n y i = 1 , ⋯ , m subject \ to \quad y_i(w \cdot x_i + b) \geq 1 - \zeta_i \quad \zeta \geq 0 \quad for \ any \ i = 1, \cdots , m s u b j e c t t o y i ( w ⋅ x i + b ) ≥ 1 − ζ i ζ ≥ 0 f o r a n y i = 1 , ⋯ , m
nu-SVM
由于 C C C v v v
max α − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j \max_\alpha \ -\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \cdot x_j α max − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i ⋅ x j
s u b j e c t t o 0 ≤ α i ≤ 1 m , subject \ to \quad 0 \leq \alpha_i \leq \frac{1}{m}, s u b j e c t t o 0 ≤ α i ≤ m 1 ,
∑ i = 1 m α i y i = 0 \sum_{i=1}^{m}\alpha_iy_i=0 i = 1 ∑ m α i y i = 0
∑ i = 1 m α i ≥ v f o r a n y i = 1 , ⋯ , m \sum_{i=1}^{m}\alpha_i \geq v \quad \ for \ any \ i = 1, \cdots , m i = 1 ∑ m α i ≥ v f o r a n y i = 1 , ⋯ , m
第四部分:合页损失函数(Hinge Loss) 那么我们继续说说 C C C
我们把支持向量机和逻辑回归的损失函数做一下对比:
Logistic Regressionmin θ 1 m [ ∑ i = 1 m y ( i ) ( − l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) ( − l o g ( 1 − h θ ( x ( i ) ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 \min_{\theta}\frac{1}{m}\Big[\sum_{i=1}^{m}y^{(i)}(-log \ h_\theta(x^{(i)})+(1-y^{(i)})(-log(1-h_\theta(x^{(i)})))\Big]+\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_j^2 θ min m 1 [ i = 1 ∑ m y ( i ) ( − l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) ( − l o g ( 1 − h θ ( x ( i ) ) ) ) ] + 2 m λ j = 1 ∑ n θ j 2
SVMmin θ C [ ∑ i = 1 m y ( i ) ( c o s t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) ( c o s t 0 ( θ T x ( i ) ) ] + 1 2 ∑ j = 1 n θ j 2 \min_{\theta}C\Big[\sum_{i=1}^{m}y^{(i)}(cost_1(\theta^Tx^{(i)})+(1-y^{(i)})(cost_0(\theta^Tx^{(i)})\Big]+\frac{1}{2}\sum_{j=1}^{n}\theta_j^2 θ min C [ i = 1 ∑ m y ( i ) ( c o s t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) ( c o s t 0 ( θ T x ( i ) ) ] + 2 1 j = 1 ∑ n θ j 2
注意到这里 m m m c o s t 1 cost_1 c o s t 1 c o s t 2 cost_2 c o s t 2
如上图所示,当 θ T x ( i ) ≥ 1 \theta^Tx^{(i)} \geq 1 θ T x ( i ) ≥ 1 0 0 0 y ( i ) = 1 y^{(i)} = 1 y ( i ) = 1 θ T x ( i ) ≤ − 1 \theta^Tx^{(i)} \leq -1 θ T x ( i ) ≤ − 1 0 0 0 y ( i ) = 0 y^{(i)} = 0 y ( i ) = 0
所以问题被转换成:
min θ 1 2 ∑ j = 1 n θ j 2 \min_\theta \frac{1}{2}\sum_{j=1}^{n}\theta_j^2 θ min 2 1 j = 1 ∑ n θ j 2
s . t . { θ T x ( i ) ≥ 1 i f y ( i ) = 1 θ T x ( i ) ≤ − 1 i f y ( i ) = 0 s.t. \quad\left\{ \begin{aligned} \theta^Tx^{(i)} &\geq 1 \quad if \ y^{(i)}=1\\ \theta^Tx^{(i)} &\leq -1 \quad if \ y^{(i)}=0 \end{aligned} \right. s . t . { θ T x ( i ) θ T x ( i ) ≥ 1 i f y ( i ) = 1 ≤ − 1 i f y ( i ) = 0
第五部分:核函数(kernel)
特征转换 思考一下,我们可以对非线性可分的数据进行分类么?也就是我们如果不能用一条直线或者一个平面对数据进行分类,我们要做的就是特征转换 (feature transformation)。
举个例子,我们对于二维的向量 ( x 1 , x 2 ) (x_1,x_2) ( x 1 , x 2 ) ϕ : R 2 → R 3 \phi: \mathbb R^2 \rarr \mathbb R^3 ϕ : R 2 → R 3
ϕ ( x 1 , x 2 ) = ( x 1 2 , 2 x 1 x 2 , x 2 2 ) \phi(x_1,x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2) ϕ ( x 1 , x 2 ) = ( x 1 2 , 2 x 1 x 2 , x 2 2 )
但是我们怎么确定要去选哪种转换方法呢?
这极大程度上取决于我们的数据集。选对正确的转换方法是成功之匙,但是并没有一个很明确的规定可以帮助我们确定选哪种转换方法,建议阅读一下scikit-learn的资料 来加深对数据预处理的理解。
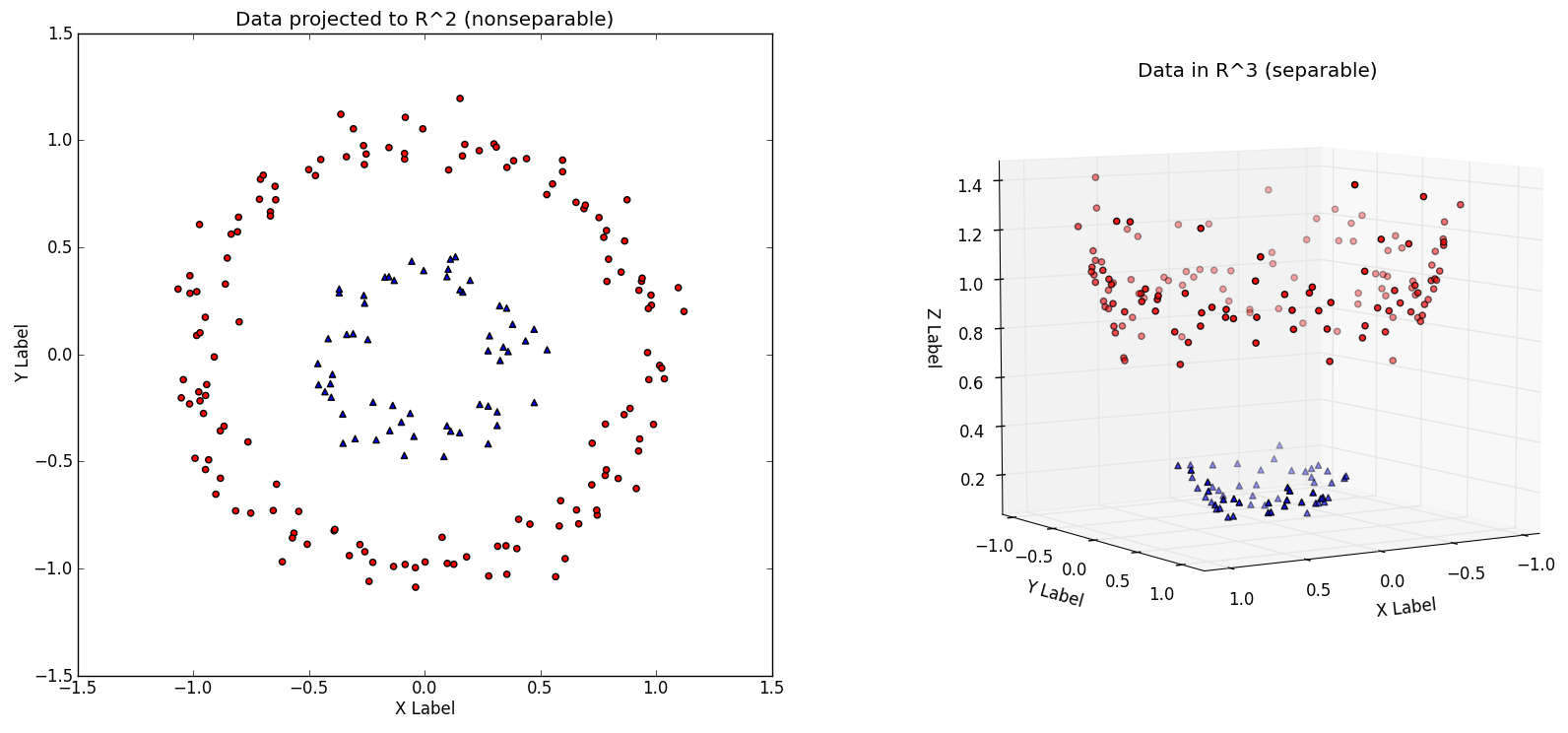
什么是核函数? 刚才我们提到了如何处理非线性可分的数据集,但是一大缺点就是我们必须对数据集中所有的点都进行转换,如果数据量太大的话,这个过程将会十分复杂,核函数应运而生!
在前一部分讨论支持向量机的对偶问题时,我们在 Wolfe 对偶拉格朗日方程中得到了满足 KKT 条件的拉格朗日乘子,其中我们是不需要计算每个训练样本的具体值的,我们实际只需要计算一对训练样本的点积 x i ⋅ x j x_i \cdot x_j x i ⋅ x j
W ( α ) = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j W(\alpha) = \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \cdot x_j W ( α ) = i = 1 ∑ m α i − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i ⋅ x j
那么是否有一种办法在不对向量进行转化就能求出这个值呢?
核函数就是来干这个的!实际上,核函数就是可以返回另一个更高维的空间里的点积的函数。
Kernel Trick 那么我们可以定义一个核函数为 K ( x i , x j ) = x i ⋅ x j K(x_i,x_j) = x_i \cdot x_j K ( x i , x j ) = x i ⋅ x j
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i K ( x i , x j ) \max_\alpha \ \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i K(x_i,x_j) α max i = 1 ∑ m α i − 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i K ( x i , x j )
s u b j e c t t o 0 ≤ α i ≤ C , f o r a n y i = 1 , ⋯ , m subject \ to \quad 0 \leq \alpha_i \leq C, \ for \ any \ i = 1, \cdots , m s u b j e c t t o 0 ≤ α i ≤ C , f o r a n y i = 1 , ⋯ , m
∑ i = 1 m α i y i = 0 \sum_{i=1}^{m}\alpha_iy_i=0 i = 1 ∑ m α i y i = 0
核函数的种类
线性核函数(Linear kernel)K ( x , x ′ ) = x ⋅ x ′ K(x,x') = x \cdot x' K ( x , x ′ ) = x ⋅ x ′
多项式核函数(Polynomial Kernel)K ( x , x ′ ) = ( x ⋅ x ′ + c ) d K(x,x') = (x \cdot x' +c)^d K ( x , x ′ ) = ( x ⋅ x ′ + c ) d
高斯核函数(RBF or Gaussian kernel)K ( x , x ′ ) = e x p ( − γ ∣ ∣ x − x ′ ∣ ∣ 2 ) K(x,x') = exp(-\gamma||x-x'||^2) K ( x , x ′ ) = e x p ( − γ ∣ ∣ x − x ′ ∣ ∣ 2 ) R ∞ \mathbb R^\infty R ∞ 这里 。γ \gamma γ g a m m a gamma g a m m a
那么我们应该选用什么核函数最好呢?很抱歉这个也是没有固定方法的,一般来说,我们会先尝试高斯核函数(RBF),核函数作为一种表示两个向量间相似程度大小的方法,我们也可以自定义核函数来实现。
延伸:SMO算法 我们已经知道如何解决SVM最优化问题了,然而实际当中我们会用一个更好的方法来更快地解决这个问题:SMO算法 。大多数机器学习的包都会用到SMO算法或其变式。
SMO算法解决下面的问题
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i K ( x i , x j ) − ∑ i = 1 m α i \min_\alpha \ \frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i K(x_i,x_j) - \sum_{i=1}^{m}\alpha_i α min 2 1 i = 1 ∑ m j = 1 ∑ m α i α j y i y j x i K ( x i , x j ) − i = 1 ∑ m α i
s u b j e c t t o 0 ≤ α i ≤ C , f o r a n y i = 1 , ⋯ , m subject \ to \quad 0 \leq \alpha_i \leq C, \ for \ any \ i = 1, \cdots , m s u b j e c t t o 0 ≤ α i ≤ C , f o r a n y i = 1 , ⋯ , m
∑ i = 1 m α i y i = 0 \sum_{i=1}^{m}\alpha_iy_i=0 i = 1 ∑ m α i y i = 0
注意我们把之前的最大化改成最小化,并加了一个负号。这个就是之前我们的核函数化后的软间隔公式。下面是用 Python 实现的代码
def kernel ( x1, x2) :
return np. dot( x1, x2. T)
def objective_function_to_minimize ( X, y, a, kernel) :
m, n = np. shape( X)
return 1 / 2 * np. sum ( [ a[ i] * a[ j] * y[ i] * y[ j] * kernel( X[ i, : ] , X[ j, : ] )
for j in range ( m)
for i in range ( m) ] ) \
- np. sum ( [ a[ i] for i in range ( m) ] )
在我们处理非常大的数据集时,在利用凸优化包时常常会包含大量的矩阵运算,从而随着矩阵规模变大花费太多时间甚至超出存储范围。
SMO算法的核心思想 当我们求解SVM对偶问题时,我们可以随便改变拉格朗日乘子 α \alpha α α = ( α 1 , α 2 , ⋯ , α m ) \alpha = (\alpha_1, \alpha_2, \cdots, \alpha_m) α = ( α 1 , α 2 , ⋯ , α m )
那么SMO算法的核心就是:给定一个 α = ( α 1 , α 2 , ⋯ , α m ) \alpha = (\alpha_1, \alpha_2, \cdots, \alpha_m) α = ( α 1 , α 2 , ⋯ , α m ) α \alpha α α \alpha α
SMO的一大优势在于求解两个拉格朗日乘子是可以求其分析解的。因此,尽管SMO 执行了更多的子优化问题,每一个子问题都会更快的被解决。
补充内容:
强烈建议阅读前三个!
实际应用和代码展示 SVM相关面经和其他资料 小结 我们在本节中深度探讨了其原理、核心思想、数学推导、延伸算法以及代码实现。支持向量机(SVM)作为一个在特征空间里寻找最大间隔的线性分类器,由于分类结果仅跟支持向量有关,无需依赖全部数据,并在特征维度大于样本数时依然有很好的效果,通过使用核函数来灵活解决各种非线性的分类回归问题。