时间序列数据的特征工程总结
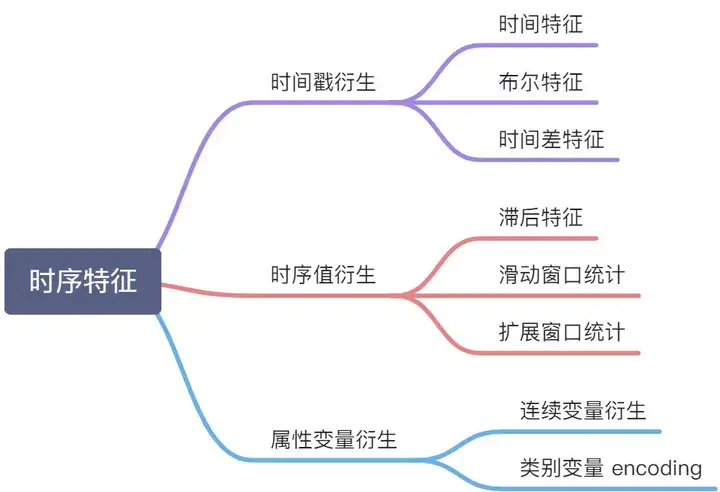
时间序列数据的特征工程总结1. 时间戳衍生的特征1.1 时间特征1.2 布尔特征1.2.1 布尔特征的好处:1.2.2 可构造的布尔特征:1.2.3 其他可能的布尔特征:1.3 时间差特征1.3.1 时间差特征的好处:1.3.2 可构造的时间差特征:2. 时序值衍生的特征2.1 滞后值(lag feature)2.2 滑动窗口统计(Rolling Window Statistics)2.3 扩展窗口统计3. 序列属性衍生的特征3.1 连续变量衍生3.2 类别变量Encoding3.2.0 变量类型3.2.1 Label Encoding(标签编码)3.2.2 One-Hot Encoding(独热编码)3.2.2 Target Encoding(目标编码)4. 波峰波谷特征4.1 全局特征4.2 窗口局部特征4.3 其他5. 周期特征5.1 周期因子特征5.1.1 方法15.1.2 方法26. 其他变换6.1 正余弦变换6.2 样条转换
当下时间序列预测的方法主要有三种
第一个是传统的时间序列预测方法,典型代表有ARIMA和指数平滑法
第二个是基于机器学习的方法,目前用的最多的是lightgbm和xgboost
第三个是基于深度学习的方法,如RNN、LSTM等
现在传统时序预测的方法的预测精度都已经不如基于机器学习和深度学习的方法了,但是后者依赖于特征工程,特征调教的好的话是可以达到很高的预测精度的
一个典型的时间序列数据,会包含以下几列:时间戳,时序值,序列的属性变量,比如下图,日期就是时间戳,销量就是时序值,如果是多序列的话可能还会有序列的属性变量,如城市、产品、价格等。
除了销售数据之外,时间序列数据可以包括各种不同类型的信息。以下是另一个典型的时间序列数据的示例:
数据类型:气象观测数据
时间戳(时间戳列): 记录每个观测时间点的日期和时间。
时序值(时序值列): 记录与每个时间点相关的气象测量值,如温度、湿度、风速等。
序列的属性变量:
地点(城市): 记录每个观测点的地理位置,比如城市名。
观测类型: 记录所测量的气象参数类型,如温度、湿度、降水量等。
示例数据:
| 时间戳 | 温度 (摄氏度) | 湿度 (%) | 风速 (m/s) | 城市 | 观测类型 |
|---|---|---|---|---|---|
| 2024-03-22 00:00:00 | 20 | 60 | 2 | 北京 | 温度 |
| 2024-03-22 00:00:00 | 25 | 50 | 3 | 上海 | 温度 |
| 2024-03-22 00:00:00 | 18 | 70 | 1 | 广州 | 温度 |
| 2024-03-22 03:00:00 | 19 | 65 | 2.5 | 北京 | 温度 |
| 2024-03-22 03:00:00 | 24 | 55 | 3.2 | 上海 | 温度 |
| 2024-03-22 03:00:00 | 17 | 75 | 1.8 | 广州 | 温度 |
| ... | ... | ... | ... | ... | ... |
1. 时间戳衍生的特征
时间戳虽然只有一列,但是也可以根据这个就衍生出很多很多变量了,具体可以分为三大类:时间特征、布尔特征,时间差特征
1.1 时间特征
年
季度
月
周
天:一年、一月、一周的第几天
小时
分钟
...
1.2 布尔特征
1.2.1 布尔特征的好处:
捕捉周期性模式: 布尔特征可以捕捉数据中的周期性模式,比如是否是年初/年末、月初/月末、周末等,这些周期性因素可能对时间序列数据具有显著影响。
引入额外信息: 布尔特征可以引入与预测目标相关的额外信息,比如节假日、特殊日期等,这些信息可能会对时间序列的波动性产生重要影响。
增强模型解释性: 布尔特征的引入可以增强模型的解释性,使得模型的预测结果更容易解释。
1.2.2 可构造的布尔特征:
是否年初/年末: 根据日期特征,判断是否为年初或年末。
是否月初/月末: 根据日期特征,判断是否为月初或月末。
是否周末: 根据日期特征,判断是否为周六或周日。
是否节假日: 使用日历信息,判断日期是否为节假日。
是否特殊日期: 判断是否为特殊日期,比如双十一、圣诞节等,这些日期可能会对数据产生特殊影响。
是否早上/中午/晚上: 根据时间特征,判断是否为早上、中午或晚上,这些时间段可能与人们的行为模式相关。
1.2.3 其他可能的布尔特征:
天气条件: 根据天气数据,构造布尔特征表示某种天气条件是否发生,比如是否下雨、是否有雾霾等。(貌似没用)
经济指标: 根据经济数据,构造布尔特征表示某种经济指标是否达到某个阈值,比如是否为经济低迷期等。(可以试试)
事件影响: 根据事件发生的数据,构造布尔特征表示某种事件是否发生,比如是否有重大新闻、是否有特定活动等。(得自己去查)
1.3 时间差特征
时间差特征(或距离特征)是指与某个特定时间点或事件之间的时间差
1.3.1 时间差特征的好处:
丰富特征表达:时间差特征可以提供关于时间的更多信息,丰富了特征空间。通过距离不同时间点的时间差,可以捕捉到时间的周期性、趋势性等特征,有助于更好地描述数据的变化规律。
增强模型预测能力:时间差特征可以为模型提供更多的信息,从而提高模型的预测能力。例如,距离重要日期(如节假日、特殊日期)的时间差可能会影响到销售额或交易量等,通过构造相应的时间差特征,模型能够更好地学习到这些影响因素。
解释模型预测结果:时间差特征可以帮助解释模型的预测结果。例如,模型预测某个时间点的销售额增加了,而与某个特殊日期的时间差减少了,那么可以推断出这个特殊日期可能与销售额增加有关。
1.3.2 可构造的时间差特征:
距离年初/年末的天数
距离月初/月末的天数
距离周末的天数
距离节假日的天数
距离特殊日期的天数
距离自定义事件的天数
2. 时序值衍生的特征
它们是从当前时间点之前的历史数据中派生出来的,可以帮助发现时间序列数据中的趋势、季节性周期性因素以及一些不规则的变动。具体来说,这些衍生特征可以分为三种类型:
滞后值(Lag Values):滞后值是指将时序数据在时间上向后推移一定的步长,从而构造新的特征。例如,对于某个时间序列变量,可以构造其一期前、两期前、三期前等的滞后值作为新的特征。通过引入滞后值特征,可以捕捉到时间序列数据的自相关性,即当前时刻的值与过去时刻的值之间的关系。
滑动窗口统计(Rolling Window Statistics):滑动窗口统计是指在时间序列数据中,以固定大小的窗口对数据进行滑动,并在每个窗口内计算统计指标。常见的统计指标包括平均值、标准差、最大值、最小值等。通过引入滑动窗口统计特征,可以在一定程度上平滑时间序列数据,减少噪声的影响,同时还能够捕捉到数据的趋势性和周期性。
拓展窗口统计(Expanding Window Statistics):拓展窗口统计是指在时间序列数据中,逐步扩大窗口的大小,并在每个窗口内计算统计指标。与滑动窗口统计不同,拓展窗口统计考虑了整个历史数据的影响,可以更好地反映数据的长期趋势。常见的拓展窗口统计指标包括累积和、累积均值等。
2.1 滞后值(lag feature)
也称lag feature,滞后特征是指将时间序列数据在时间轴上向后推移一定步长所得到的特征。
在预测任务中,我们通常认为当前时刻的数据与过去某些时刻的数据具有相关性,因此可以将这些过去时刻的数据作为特征,帮助预测当前时刻的目标值。比如,对于某个时间序列变量,在预测 t 时刻的值时,可以将 t-1、t-7、t-30、t-365 时刻的数据作为特征。
在多步预测任务中,如果要预测的时间范围超过了滞后期数,就会出现数据不匹配的情况。以一个具体的例子来说明这个问题:
假设我们要预测 2021-07-11 和 2021-07-12 两天的数据,而我们的滞后特征仅包含了 t-1 的数据(即 2021-07-10 的数据)。在这种情况下,我们希望使用 2021-07-10 的数据作为特征来预测 2021-07-11 的数据,因为此时有可用的特征。但是,当我们想要预测 2021-07-12 的数据时,由于没有 2021-07-11 的数据作为特征,我们无法直接使用 t-1 的特征来进行预测。
因此,为了解决这个问题,我们需要一种方法来填补这个缺失的特征。一种常见的方法是使用已经预测的值作为特征。具体来说,我们可以先用 t-1 的特征来预测 2021-07-11 的数据,得到预测值,然后将这个预测值作为 t-1 的特征,再用它来预测 2021-07-12 的数据。这样就可以逐步迭代地预测每一步的数据,每次都使用上一步的预测值作为特征输入。
2.2 滑动窗口统计(Rolling Window Statistics)
除了使用原始Lag值作为特征,还可以使用先前时间观察值的统计信息作为特征,这种类型的特征叫做滑动窗口统计,Rolling Window Statistics。
具体来说,对于某个特定时刻t,滑动窗口统计会考虑在过去一段时间窗口内的数据,并计算该窗口内数据的统计信息,如平均值、中位数、标准差、最大值、最小值等。这个时间窗口的大小由用户指定,通常以天为单位。
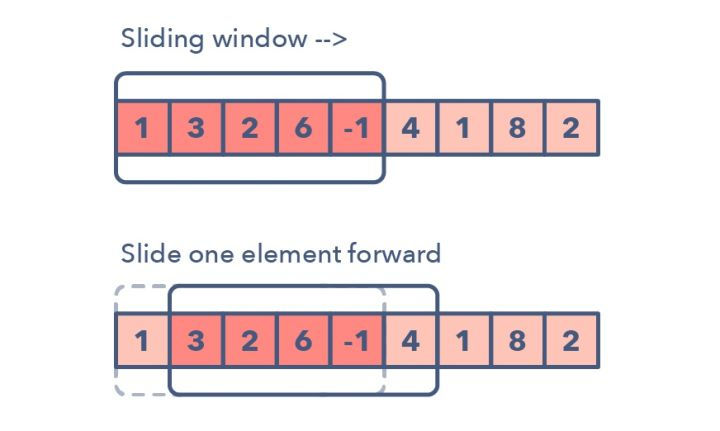
举个例子,如果将窗口大小设定为7天,那么对于时刻t,滑动窗口统计会考虑时刻t-1到t-7的数据,并计算这7天内数据的统计信息作为新的特征。这样可以利用过去一周的数据情况来帮助预测当前时刻的目标值。
需要注意的是,滑动窗口统计也可以根据需要指定不同的窗口大小,如14天、30天等,以获取不同时间跨度的数据统计信息。此外,还要注意在构造这种特征时可能会遇到多步预测时的问题,需要考虑好窗口大小和预测步长之间的关系,以避免引入过多的时间偏差或数据泄漏。
2.3 扩展窗口统计
另一种特征叫做扩展窗口统计(Expanding Window Statistics),其实也算是一种特殊的滑动窗口统计,不过他用来统计的数据是整个序列全部的数据。
这种方法的思想是逐步扩大窗口,从序列的开始到当前位置,逐步增加数据量来计算统计指标。这样做的好处是能够利用序列中所有数据的信息,得到更加全面和准确的统计特征。通常可以计算的统计特征包括平均数、中位数、标准差、最大值、最小值等。
扩展窗口统计特征提供了一种方法来捕捉序列内部的规律和变化,因为它考虑了整个序列的全部数据,而不仅仅是局部窗口的数据。通过计算统计指标,如平均数、中位数、标准差等,可以更好地描述序列的整体趋势和波动性。这样的特征能够为每个序列提供更具代表性的描述,从而使模型能够更好地理解和区分不同序列之间的差异。
3. 序列属性衍生的特征
3.1 连续变量衍生
一个序列可能会伴有多个连续变量的特征,比如说对于股票数据,除了收盘价,可能还会有成交量、开盘价等伴随的特征,对于销量数据,可能还会伴随有价格的特征。对于这种连续变量,可以直接作为一个特征,也可以像之前时序值衍生的特征那样做处理,或者也可以与先前的数据做差值,比如t时刻的价格减去t-1时刻的价格。但是一般这种连续变量使用不多,因为这些值在未来也很可能是不可知的,那怎么能当成造特征呢?
3.2 类别变量Encoding
对于类别型变量,如果类别比较少,一般在机器学习里做的处理是one-hot encoding,但是如果类别一多,那么生成的特征是会很多的,容易造成维度灾难,但是也不能随便用label encoding,因为很多时候类别是不反应顺序的,如果给他编码成1、2、3、4、5,对于一些树模型来说,在分裂节点的时候可不管这些是类别型还是连续型,通通当作连续型来处理,这是有先后顺序的,肯定不能这么做。所以就有这么一种方式,就是和y做特征交互,比如预测销量,有一个特征是产品类别,那么就可以统计下这个产品类别下的销量均值、标准差等,这种其实也算是上面扩展窗口统计的一种。
3.2.0 变量类型
A. 二元特征: 二元特征通常表示两种互斥的状态或选择。这意味着一个对象只能同时具有其中的一种状态。在二元特征中,每个类别代表了一个明确的情况或选择。例如:
是/否:表示是否发生了某个事件或条件是否成立。
真/假:表示某个断言的真实性或有效性。
在二元特征中,每个类别之间通常存在明确的对立关系,而且两个类别通常具有相似的重要性。
B. 有序特征: 有序特征表示具有一定顺序或级别关系的类别。这意味着在这种特征中,每个类别都有一个明确的顺序,其中某些类别被认为是更高或更重要的。例如:
低/中/高:表示某种级别或程度的大小顺序。
冷/热/岩浆热:表示温度的不同级别,其中某些级别被认为比其他级别更高。
在有序特征中,类别之间的顺序关系对于数据的解释和分析至关重要。通常,这种特征表示的是一种连续性的变化或级别。
C. 名义特征: 名义特征代表的是一组没有任何内在顺序或级别关系的类别。这意味着在名义特征中,每个类别都是彼此独立的,没有明确的顺序。例如:
猫/狗/老虎:表示不同类型的动物,它们之间没有明确的顺序关系。
披萨/汉堡/可乐:表示不同种类的食物或饮料,它们之间没有大小或重要性的顺序。
在名义特征中,每个类别都被视为是独立的,没有顺序关系。因此,在分析和建模时,名义特征的类别通常被视为是相互独立的。
3.2.1 Label Encoding(标签编码)

标签编码是一种将类别型特征转换为整数标签的编码方法。标签编码的过程很简单,就是将每个类别按照它们在数据中出现的顺序赋予一个整数编码。例如,如果一个特征包含了三个类别:'A'、'B'、'C',则可以用0、1、2分别代表它们。这样,原始的类别型特征就被转换为了整数编码。
优点包括:
简单快捷: 标签编码的实现非常简单,可以直接使用许多机器学习库提供的函数来完成。
保留类别信息: 虽然将类别转换为整数编码,但是整数之间的顺序没有实际意义,因此它仍然保留了原始特征中的类别信息。
然而,标签编码也存在一些缺点:
可能误导模型: 对于一些机器学习算法,如决策树和随机森林,它们可能会错误地将整数编码解释为有序的特征,从而影响模型的性能。
因此,在使用标签编码时需要注意一些问题:
如果类别之间不存在顺序关系,应该谨慎使用标签编码,或者在使用之前仔细检查数据是否具有顺序性。
xxxxxxxxxx181from sklearn.preprocessing import LabelEncoder2
3# 假设有一个类别型特征4categories = ['cat', 'dog', 'mouse', 'cat', 'dog']5
6# 创建 LabelEncoder 对象7label_encoder = LabelEncoder()8
9# 对类别进行标签编码10encoded_categories = label_encoder.fit_transform(categories)11
12# 输出编码结果13print("原始类别:", categories)14print("标签编码结果:", encoded_categories)15
16# 可以使用 inverse_transform 方法将编码结果逆转回原始类别17decoded_categories = label_encoder.inverse_transform(encoded_categories)18print("逆转后的类别:", decoded_categories)3.2.2 One-Hot Encoding(独热编码)
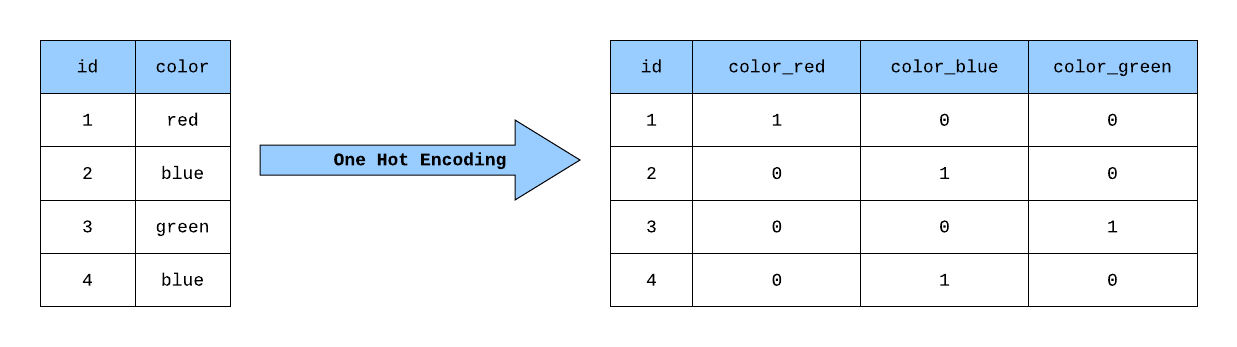
用于将类别型特征转换为二进制编码。在独热编码中,每个类别都由一个长度等于类别总数的向量表示,其中只有一个元素为1(表示类别存在),其他元素为0。
xxxxxxxxxx161from sklearn.preprocessing import OneHotEncoder2import numpy as np3
4# 假设有一个包含三个类别的特征数据5categories = np.array(['red', 'blue', 'green']).reshape(-1, 1)6
7# 创建并拟合OneHotEncoder对象8encoder = OneHotEncoder()9encoder.fit(categories)10
11# 对类别进行独热编码12one_hot_encoded = encoder.transform(categories).toarray()13
14# 打印独热编码后的结果15print("独热编码后的结果:")16print(one_hot_encoded)
优点:
保留了类别之间的无序性:独热编码将每个类别表示为一个独立的向量,这样可以确保不同类别之间没有顺序关系,适用于无序类别的特征。
避免了类别之间的顺序关系:由于每个类别都用独立的向量表示,因此独热编码不会引入类别之间的顺序关系,避免了模型对类别之间的顺序进行错误的假设。
缺点:
维度灾难:如果类别数量较多,独热编码会导致特征空间的维度急剧增加,从而增加了模型的复杂度和训练时间。这在处理大规模数据时可能会成为一个问题。
冗余性:独热编码会生成多个特征,其中大多数特征都是稀疏的(大部分值为0),这可能会导致数据集中存在大量冗余信息,增加了计算和存储的成本。
不适用于高基数特征:对于具有高基数(大量不同取值)的特征,独热编码会生成过多的特征,导致维度爆炸和稀疏性问题。这种情况下,通常需要使用其他编码方法或特征选择技术来处理。
3.2.2 Target Encoding(目标编码)
![Data frame analytics feature processors | Machine Learning in the Elastic Stack [7.17] | Elastic](https://www.elastic.co/guide/en/machine-learning/7.17/images/target-mean-encoding.jpg)
也称为Mean Encoding或Probability Encoding,是一种用于处理分类特征的编码方法。它将每个类别映射到目标变量(通常是二元分类问题中的目标类别的概率或均值),从而将分类特征转换为数值特征。
目标编码的基本思想是利用目标变量在不同类别下的分布情况来编码分类特征,以反映不同类别对目标变量的影响程度。
xxxxxxxxxx11df["feature_te"] = df.groupby("feature")["target"].transform("mean")3.2.3 其他
xxxxxxxxxx271# pip install category_encoders2
3import category_encoders as ce4
5encoder = ce.BackwardDifferenceEncoder(cols=[...])6encoder = ce.BaseNEncoder(cols=[...])7encoder = ce.BinaryEncoder(cols=[...])8encoder = ce.CatBoostEncoder(cols=[...])9encoder = ce.CountEncoder(cols=[...])10encoder = ce.GLMMEncoder(cols=[...])11encoder = ce.GrayEncoder(cols=[...])12encoder = ce.HashingEncoder(cols=[...])13encoder = ce.HelmertEncoder(cols=[...])14encoder = ce.JamesSteinEncoder(cols=[...])15encoder = ce.LeaveOneOutEncoder(cols=[...])16encoder = ce.MEstimateEncoder(cols=[...])17encoder = ce.OneHotEncoder(cols=[...])18encoder = ce.OrdinalEncoder(cols=[...])19encoder = ce.PolynomialEncoder(cols=[...])20encoder = ce.QuantileEncoder(cols=[...])21encoder = ce.RankHotEncoder(cols=[...])22encoder = ce.SumEncoder(cols=[...])23encoder = ce.TargetEncoder(cols=[...])24encoder = ce.WOEEncoder(cols=[...])25
26encoder.fit(X, y)27X_cleaned = encoder.transform(X_dirty)BackwardDifferenceEncoder: 使用类别值的差异来编码特征。每个编码的特征表示为该类别与其后续类别的差异。这种编码通常用于处理有序分类变量。
BaseNEncoder: 将类别值转换为基数N的数字。例如,对于类别A、B、C,可能会转换为0、1、2(如果N=3),或者转换为10、11、12(如果N=13)等。
BinaryEncoder: 将类别值转换为二进制编码。每个类别值被表示为一串二进制数字。
CatBoostEncoder: CatBoost是一种梯度提升算法,该编码器使用CatBoost模型来对类别特征进行编码。
CountEncoder: 将每个类别值替换为其在整个数据集中出现的次数。
GLMMEncoder: 使用广义线性混合模型(Generalized Linear Mixed Model)来编码类别特征。
GrayEncoder: 使用格雷编码(Gray Code)来对类别特征进行编码。格雷编码是一种二进制编码,相邻的两个数之间只有一个比特位不同。
HashingEncoder: 将类别值哈希成固定数量的特征列。这种编码通常用于处理高基数的类别特征。
HelmertEncoder: 使用Helmert转换来编码类别特征。Helmert转换是一种多重比较方法,用于比较每个类别与其后续类别的差异。
JamesSteinEncoder: 使用James-Stein估计来编码类别特征。
LeaveOneOutEncoder: 将每个类别值替换为在该类别上目标变量的平均值,但排除了当前样本。
MEstimateEncoder: 使用M估计来编码类别特征。
OneHotEncoder: 将类别特征转换为独热编码形式,即每个类别值被表示为一个只有一个元素为1,其他元素为0的向量。
OrdinalEncoder: 将类别特征转换为顺序编码,即将类别值映射到整数值。
PolynomialEncoder: 使用多项式基函数来编码类别特征。
QuantileEncoder: 将类别值替换为其在整个数据集中的分位数。
RankHotEncoder: 将类别值转换为其在整个数据集中的排名。
SumEncoder: 使用和编码来编码类别特征,即每个类别值与其他类别值的和。
TargetEncoder: 将每个类别值替换为目标变量在该类别上的平均值。
WOEEncoder: 使用权重的编码来编码类别特征,其中权重是目标变量的对数几率比。
4. 波峰波谷特征
波峰和波谷是非常重要的特征,它们反映了数据的局部极值点,通常用于分析周期性、震荡性等特征。
4.1 全局特征

4.2 窗口局部特征
窗口大小:10天

窗口大小:30天

4.3 其他
xxxxxxxxxx121波峰数量: 162波谷数量: 153波峰位置: [ 4 16 22 24 28 36 43 47 64 67 72 74 79 81 85 97]4波谷位置: [ 5 20 23 25 33 42 46 63 66 68 73 76 80 83 88]5波峰值: [ 0.43544569 0.99373583 1.06873087 1.22500219 1.13556517 0.8935423160.62085683 0.26513035 -0.75277063 -0.83002845 -0.86834718 -0.957792567-0.96296663 -0.83969384 -0.61942808 -0.00879427]8波谷值: [ 0.21128921 0.69575753 0.9178982 0.85456343 0.67822703 0.3111266690.12341035 -0.90159689 -1.00734776 -0.99555689 -1.11559728 -1.0851064410-1.0675715 -1.02993105 -0.79162237]11波峰间隔: [12 6 2 4 8 7 4 17 3 5 2 5 2 4 12]12波谷间隔: [15 3 2 8 9 4 17 3 2 5 3 4 3 5]
5. 周期特征
支付数据、客流量数据、交通数据等时间序列,通常都具有比较明显的周期性,我们可以利用数据的周期性的变化,总结出简单的规则进行预测。
其基本的步骤为:
选择特征
可以用简单的统计量来作为特征,从中提取出有用的信息。
xxxxxxxxxx311)中位数:居于中间位置的数,较为稳健22)均值:当分布符合正态分布时,可以代表整体特征33)临近数据:离待测数据越近的数据对其影响越大Copy
确定组成一个周期的元素(1号~31号),一周或者一个月;
结合STL分解观察周期的变化;
STL(Seasonal and Trend decomposition using Loess)分解是一种常用的时间序列分解方法,用于将时间序列分解为季节性、趋势性和残差三个部分。
季节性分解(Seasonal decomposition): 使用 Loess 方法拟合原始序列的季节性部分,得到季节性趋势。Loess 方法是一种非参数的局部回归平滑方法,它通过对每个数据点周围的近邻数据进行加权平均来拟合局部的回归模型。
趋势性分解(Trend decomposition): 对于去除了季节性的序列,再次使用 Loess 方法拟合趋势性部分,得到趋势性趋势。
残差计算(Residual calculation): 将原始序列减去季节性趋势和趋势性趋势,得到残差序列,即原始序列中除了季节性和趋势性以外的部分。
基于周期因子的缺点是没有办法考虑到节假日与突发事件的影响
| 星期 | 周一 | 周二 | 周三 | 周四 | 周五 | 周六 | 周日 | 周均值 |
|---|---|---|---|---|---|---|---|---|
| week 1 | 20 | 10 | 70 | 50 | 250 | 200 | 100 | 100 |
| week 2 | 26 | 18 | 66 | 50 | 180 | 140 | 80 | 80 |
| week 3 | 15 | 8 | 67 | 60 | 270 | 160 | 120 | 100 |
通过给定前3周的数据,目标是预测第四周每天的客流量。可以发现,从周一到周日,数据存在明显的周期性波动,预测的主要目的就是尽量准确的将这种周期的波动提取出来。
5.1 周期因子特征
5.1.1 方法1
除以周均值,之后按列取中位数
| 星期 | 周一 | 周二 | 周三 | 周四 | 周五 | 周六 | 周日 |
|---|---|---|---|---|---|---|---|
| 第一周 | 0.2 | 0.1 | 0.7 | 0.5 | 2.5 | 2 | 1 |
| 第二周 | 0.325 | 0.225 | 0.825 | 0.625 | 2.25 | 1.75 | 1 |
| 第三周 | 0.15 | 0.08 | 0.67 | 0.6 | 2.7 | 1.6 | 1.2 |
| 中位数 | 0.2 | 0.1 | 0.7 | 0.6 | 2.5 | 1.75 | 1 |
除以周均值: 首先,对于每个星期中的每一天,计算该天的数据除以该星期的均值。例如,对于第一周的周一,将周一的数据除以第一周的均值;对于第二周的周一,将周一的数据除以第二周的均值,依此类推。
按列取中位数: 然后,对于每一列(即每个星期中的每一天),取所有星期中该天的数据的中位数作为该天的季节性指数。即在每个星期内,对于同一天的数据取中位数。
以表格中的数据为例,计算季节性指数的步骤如下:
对于周一,计算第一周周一、第二周周一和第三周周一的数据除以对应周的均值,得到0.2、0.325、0.15。
依此类推,计算每一天的数据除以对应周的均值。
最后,对于每一列(每一天),取所有星期中该天的数据的中位数。例如,对于周一,取0.2、0.325和0.15的中位数,得到0.2。
得到季节性指数表格,其中每一行代表一个星期,每一列代表一个星期中的一天,表格中的数值就是相应天的季节性指数。
5.1.2 方法2
季节指数的计算方式,获得每日的均值,再除以整体均值
| 星期 | 周一 | 周二 | 周三 | 周四 | 周五 | 周六 | 周日 | 周均值 |
|---|---|---|---|---|---|---|---|---|
| week 1 | 20 | 10 | 70 | 50 | 250 | 200 | 100 | 100 |
| week 2 | 26 | 18 | 66 | 50 | 180 | 140 | 80 | 80 |
| week 3 | 15 | 8 | 67 | 60 | 270 | 160 | 120 | 100 |
| 均值 | 20.33 | 12 | 67.67 | 53.33 | 233.33 | 166.67 | 100 | 93.33 |
| 因子 | 0.22 | 0.13 | 0.73 | 0.57 | 2.50 | 1.79 | 1.07 | 1 |
此外,由于中位数可能会丢失掉一定的信息,想要对周期因子进行优化,还可以通过提取均值与中位数,并按照一定的比例进行融合。
计算每日均值(Daily Mean): 对于每一天,将该天的所有数据取平均值。例如,对于周一,将所有周一的数据取平均值;对于周二,将所有周二的数据取平均值,依此类推。
计算整体均值(Overall Mean): 将所有数据的均值计算出来,得到整体的均值。
计算季节性指数(Seasonal Index): 对于每个星期中的每一天,计算该天的日均值除以整体均值,即:
季节性指数 = 该天的日均值 / 整体均值
以表格中的数据为例,计算季节性指数的步骤如下:
对于周一,日均值为20.33,整体均值为93.33,所以季节性指数为20.33 / 93.33 ≈ 0.218。
对于周二,日均值为12,整体均值为93.33,所以季节性指数为12 / 93.33 ≈ 0.129。
依此类推,计算每一天的季节性指数。
解释季节性指数(Interpretation of Seasonal Index): 季节性指数大于1表示在该天的数据通常高于整体均值,季节性指数小于1表示在该天的数据通常低于整体均值,季节性指数等于1表示在该天的数据与整体均值相当。
由于中位数可能会丢失掉一定的信息,想要对周期因子进行优化,可以通过将均值和中位数按照一定的比例进行加权融合,以得到更加平衡的季节性指数。具体而言,可以定义一个权重参数,将均值和中位数按照权重进行加权求和,从而得到最终的季节性指数。
例如,假设权重参数为
季节性指数 = α × 均值 + (1 - α) × 中位数
可以使用 Sigmoid 函数来构造
其中:
6. 其他变换
6.1 正余弦变换
使用正弦和余弦变换来对每个周期特征进行编码,其捕捉到周期性的变化
使用两个变换器函数sin_transformer和cos_transformer,用于将特征转换为对应的正弦和余弦值。
正弦和余弦函数是周期性函数,它们的周期性与特征的周期相匹配。例如,对于小时特征,其周期是24小时,而正弦和余弦函数的周期也可以相应进行配置,能够有效地编码时间特征的周期性变化。
xxxxxxxxxx121cyclic_cossin_transformer = ColumnTransformer(2 transformers=[3 ("categorical", one_hot_encoder, categorical_columns),4 ("month_sin", sin_transformer(12), ["month"]),5 ("month_cos", cos_transformer(12), ["month"]),6 ("weekday_sin", sin_transformer(7), ["weekday"]),7 ("weekday_cos", cos_transformer(7), ["weekday"]),8 ("hour_sin", sin_transformer(24), ["hour"]),9 ("hour_cos", cos_transformer(24), ["hour"]),10 ],11 remainder=MinMaxScaler(),12)6.2 样条转换
使用样条转换来编码周期性时间相关特征相对于使用正弦/余弦转换具有更大的灵活性
样条方法允许拟合更复杂的曲线,因为它们不限于简单的正弦/余弦函数形式。
样条方法具有更多可调参数的优势,例如样条的数量和阶数,以便更好地适应数据的特性。相比之下,正弦/余弦转换的参数(例如周期和相位)可能不够灵活。
xxxxxxxxxx91cyclic_spline_transformer = ColumnTransformer(2 transformers=[3 ("categorical", one_hot_encoder, categorical_columns),4 ("cyclic_month", periodic_spline_transformer(12, n_splines=6), ["month"]),5 ("cyclic_weekday", periodic_spline_transformer(7, n_splines=3), ["weekday"]),6 ("cyclic_hour", periodic_spline_transformer(24, n_splines=12), ["hour"]),7 ],8 remainder=MinMaxScaler(),9)n_splines 参数用于确定每个周期性特征的样条数量。这个参数的选择通常是基于数据的周期性和复杂性进行的。每个周期性特征都有一个固定的周期长度(例如,月份有 12 个月,星期有 7 天,小时有 24 小时)。然后,通过设置 n_splines 参数,您可以决定用多少个样条来拟合这个周期。
通常,样条数量越多,模型的拟合能力就越强,但也可能会导致过拟合。因此,需要进行一些试验来确定合适的样条数量。一种常见的做法是尝试一系列不同的样条数量,然后通过交叉验证或其他评估指标来选择最佳的样条数量,以在模型性能和泛化能力之间取得平衡。