XGBoost
XGBoostSummaryKey TakeawaysInterview QuestionsWhat is XGBoost, and how does it differ from traditional gradient boosting algorithms?Key differences between XGBoost and GBDTWhy does XGBoost use second-order Taylor expansion?How does XGBoost handle imbalanced datasets?In what scenarios is Logistic Regression (LR) preferred over Gradient Boosting Decision Trees (GBDT)?Why can XGBoost be trained in parallel? How is it trained?Explain the concept of boosting and how XGBoost utilizes it for improved predictive modeling.What are the advantages of using XGBoost over other machine learning algorithms?What regularization techniques are employed in XGBoost to prevent overfitting?How does XGBoost handle missing values in the dataset?Can you briefly explain the objective functions available in XGBoost for regression and classification tasks?What is the role of the learning rate (eta) parameter in XGBoost, and how does it affect the training process?Describe the process of early stopping in XGBoost and its purpose.How does XGBoost handle categorical variables in the dataset?What are the key hyperparameters in XGBoost, and how do they impact the model's performance?How can you assess the importance of features in an XGBoost model?What is the difference between XGBoost's tree-based and linear base learners?Explain the concept of ensemble learning and how it is utilized in XGBoost.How can you tune the hyperparameters of an XGBoost model to improve its performance?Can you compare XGBoost with Random Forest and highlight their differences and similarities?How can you interpret the output of an XGBoost model in terms of feature importance?Are there any specific scenarios or types of data where XGBoost is particularly effective or not suitable?What are some practical considerations for implementing XGBoost in a production environment?What are the differences between XGBoost and LightGBM?Python ImplementUsing SklearnHow to Train XGBoost Model With PySpark
Summary
XGBoost is a powerful gradient boosting algorithm with features including high performance, scalability, support for various loss functions and tree types, automatic handling of missing values, feature selection, and importance evaluation.
Key Takeaways
XGBoost (eXtreme Gradient Boosting) is a popular and powerful machine learning algorithm known for its exceptional performance in various tasks.
It is based on the gradient boosting framework, which sequentially adds weak models (typically decision trees) to iteratively improve the overall prediction.
XGBoost incorporates regularization techniques such as shrinkage, column subsampling, and row subsampling to prevent overfitting and enhance generalization.
It supports both classification and regression tasks, making it versatile for a wide range of predictive modeling problems.
XGBoost provides an efficient implementation that optimizes memory usage and computation speed, making it scalable to handle large datasets.
It offers a range of loss functions to accommodate different types of problems, including linear regression, logistic regression, and ranking objectives.
XGBoost can automatically handle missing values by learning their optimal direction during the tree building process.
It includes advanced features like early stopping, which allows the model to stop training early if performance on a validation set does not improve.
XGBoost provides built-in feature selection capabilities, allowing the identification of the most important features for prediction.
It supports parallel processing and can be easily integrated with other machine learning libraries, making it a popular choice among data scientists and Kaggle competition participants.
Interview Questions
What is XGBoost, and how does it differ from traditional gradient boosting algorithms?
XGBoost improves upon traditional gradient boosting algorithms by offering scalability, regularization techniques, efficient handling of missing values, optimized tree construction, and customization options. These enhancements contribute to its popularity and success in various machine learning tasks.
Scalability: XGBoost is designed to handle large-scale datasets efficiently. It implements parallelization techniques to leverage multi-core processors and distributed computing frameworks, making it faster than traditional gradient boosting algorithms.
Regularization: XGBoost introduces regularization techniques to prevent overfitting and improve generalization. It includes L1 and L2 regularization terms in the objective function to control the complexity of the model and reduce the impact of individual trees.
Handling Missing Values: XGBoost has built-in capabilities to handle missing values in the dataset. It learns the best direction to handle missing values during the tree construction process, eliminating the need for imputation or pre-processing steps.
Tree Construction: XGBoost employs a different approach to construct trees compared to traditional gradient boosting algorithms. It uses a technique called approximate tree learning, which uses quantile sketching and gradient statistics to find optimal splits efficiently.
Sparsity Awareness: XGBoost is designed to handle sparse data efficiently. It employs a data structure known as Compressed Sparse Column (CSC) to represent sparse input matrices, reducing memory usage and speeding up computations.
Customization: XGBoost provides a wide range of hyperparameters that can be tuned to customize the model behavior. It allows control over the learning rate, tree depth, subsampling, regularization parameters, and more, providing flexibility in model design.
Key differences between XGBoost and GBDT
XGBoost (eXtreme Gradient Boosting) and GBDT (Gradient Boosting Decision Trees) are both machine learning models based on gradient boosting algorithms. While they share many similarities, there are also some differences between them. Here are the main differences:
Regularization Techniques: XGBoost introduces regularization techniques, including L1 and L2 regularization, to control model complexity and prevent overfitting. By adding regularization terms in the objective function, XGBoost can effectively control tree growth and improve generalization.
Parallel Computation: XGBoost can leverage parallel computation to accelerate model training. It utilizes multi-threading for parallel computation within nodes and also supports distributed computing in a distributed environment. In contrast, GBDT constructs trees sequentially, without direct support for parallel computation.
Custom Loss Functions: XGBoost allows users to define custom loss functions to better adapt to specific problems and tasks. Users can define their own loss functions according to their needs and use them in model training. GBDT, on the other hand, only supports predefined loss functions.
Column Block Parallelism: XGBoost introduces the concept of column block parallelism, which enables more efficient handling of sparse data and high-dimensional features. It processes data in column blocks, improving computational efficiency, especially for large-scale data and high-dimensional features. GBDT does not have this column block parallelism capability.
Missing Value Handling: XGBoost can handle missing values automatically. It can learn the best splitting direction for missing values during tree construction and allocate missing values to appropriate child nodes. GBDT, on the other hand, requires manual handling of missing values during the preprocessing stage.
Feature Importance Estimation: XGBoost provides more accurate feature importance estimation methods. It calculates feature importance based on the contributions of features during the model training process, allowing for a more precise evaluation of the impact of features on the model performance. GBDT's feature importance estimation is relatively simpler, mainly based on the number of times a feature is selected as a splitting feature.
XGBoost extends GBDT by introducing regularization, parallel computation, custom loss functions, and provides more accurate feature importance estimation. These additional features make XGBoost a powerful and flexible algorithm for various machine learning tasks.
Why does XGBoost use second-order Taylor expansion?
XGBoost utilizes second-order Taylor expansion to approximate the loss function and optimize the model training process. There are several important reasons for this approximation:
More accurate approximation of the loss function: Second-order expansion provides a more accurate approximation of the loss function compared to first-order expansion. By considering the local curvature of the loss function around the current model predictions, the second-order expansion better fits the shape of the loss function, leading to a more precise optimization process.
More accurate approximation of gradients and Hessians: XGBoost uses second-order Taylor expansion to approximate the loss function and derives the corresponding expressions for first-order gradients and second-order Hessians. These approximations allow for a more accurate estimation of the gradients and Hessians of the loss function, providing reliable information for model parameter updates and optimization.
Accelerated optimization process: By using second-order expansion and approximating the gradients and Hessians, XGBoost can optimize the model more quickly. Compared to directly computing the exact gradients and Hessians, utilizing the approximations significantly reduces computational complexity, thereby speeding up the model training process.
In summary, XGBoost employs second-order Taylor expansion to approximate the loss function and utilizes approximated gradients and Hessians to accelerate the optimization process. This approximation provides a more accurate fit to the loss function and enables XGBoost to optimize the model faster and more accurately.
How does XGBoost handle imbalanced datasets?
In the case of an imbalanced dataset, where the number of samples in one class (e.g., positive examples) is significantly smaller than the other class (e.g., negative examples), it can pose challenges for training an XGBoost model effectively. The two approaches mentioned aim to address these challenges:
Balancing the positive and negative weights: By using the scale_pos_weight parameter in XGBoost, you can assign higher weights to the samples from the minority class (positive examples) compared to the majority class (negative examples). This imbalance compensation helps the model to focus more on correctly predicting the positive class, improving its performance. Additionally, using AUC (Area Under the ROC Curve) as the evaluation metric is suitable in this scenario as it measures the model's ability to rank the examples correctly, regardless of the class distribution.
Setting max_delta_step for predicting the right probability: When the goal is to predict the right probability instead of solely focusing on the ranking order, re-balancing the dataset may not be appropriate. In such cases, the
max_delta_stepparameter can be used. It limits the maximum step size during the training process and helps in achieving better convergence. Setting a finite value (e.g., 1) for max_delta_step ensures that the optimization process doesn't take large steps, preventing the model from making overly confident predictions.
In what scenarios is Logistic Regression (LR) preferred over Gradient Boosting Decision Trees (GBDT)?
Logistic Regression (LR) may be more suitable than Gradient Boosting Decision Trees (GBDT) in the following scenarios:
Linearly separable problems: When the problem is linearly separable, meaning the decision boundaries between classes are linear, logistic regression tends to perform better. LR directly models linear relationships and is well-suited for simple linear problems.
High-dimensional sparse data: LR has certain advantages when dealing with high-dimensional sparse datasets. It is easier for LR to perform feature selection in high-dimensional spaces, and it can handle zero-valued features directly without requiring additional treatment for missing values.
Interpretability requirements: If model interpretability is a high priority, logistic regression is a more intuitive and interpretable model. The coefficients in logistic regression can be used to explain the impact of each feature on the target variable, while GBDT consists of multiple decision trees, which may be more complex to interpret.
Computational efficiency: Logistic regression is a linear model with simple parameter estimation, making it computationally efficient. In contrast, GBDT requires building multiple decision trees and iterative training, which can be more computationally expensive.
It's important to note that GBDT remains a powerful model in many scenarios, especially in non-linear, non-sparse datasets, and complex feature relationships. The choice of the appropriate model depends on the characteristics of the data, complexity of the problem, and requirements of the prediction task.
Why can XGBoost be trained in parallel? How is it trained?
XGBoost can be trained in parallel due to its design and specific features. Here's how it is trained:
Feature Block Parallelism: XGBoost adopts a technique called feature block parallelism, where the dataset is divided into blocks based on feature columns. Each block can be processed independently in parallel, allowing for efficient computation, especially with sparse and high-dimensional data.
Tree Level Parallelism: Within each feature block, XGBoost leverages tree level parallelism. It parallelizes the construction of decision trees by assigning multiple threads to different tree nodes simultaneously. This parallelization accelerates the training process and improves scalability.
Column Block Splitting: XGBoost employs a technique called column block splitting, which is particularly useful when working with data that exceeds the memory capacity. It divides the feature columns into multiple column blocks, and each block is loaded and processed iteratively to conserve memory while maintaining parallelism.
Distributed Computing: XGBoost supports distributed computing, allowing the training process to be scaled across multiple machines in a cluster. It utilizes a distributed computing framework like Apache Hadoop or Apache Spark to distribute the computation and handle large-scale datasets.
In summary, XGBoost can be trained in parallel through feature block parallelism, tree level parallelism, column block splitting, and distributed computing. These techniques enable efficient computation, faster training, and scalability when working with large datasets or in distributed environments.
Explain the concept of boosting and how XGBoost utilizes it for improved predictive modeling.
Boosting is a machine learning ensemble technique that combines multiple weak models (often referred to as "learners") to create a stronger and more accurate predictive model. The idea behind boosting is to iteratively train new models that focus on correcting the mistakes made by previous models. Each new model gives more weight to the data points that were misclassified or had high prediction errors by the ensemble of previous models.
XGBoost utilizes the boosting concept to improve predictive modeling in the following way:
Initialization: XGBoost starts with an initial weak model, which is often a simple one like a decision tree with a single node.
Iterative Training: XGBoost performs a series of iterations, where each iteration involves adding a new weak model to the ensemble. The algorithm determines the best location and structure for the new model by optimizing an objective function.
Gradient Descent: XGBoost uses gradient descent optimization to train each weak model. It calculates the gradient of the loss function with respect to the predictions of the ensemble, and the new model is trained to minimize this gradient.
Weighted Updates: XGBoost assigns weights to the data points based on their importance in each iteration. The weights are updated based on the performance of the ensemble up to that point. Misclassified or high-error data points receive higher weights to allow the new model to focus on those instances.
Learning Rate: XGBoost introduces a learning rate (also known as the shrinkage parameter) that controls the contribution of each new model to the ensemble. A lower learning rate makes the ensemble learning more conservative by reducing the impact of each weak model, while a higher learning rate leads to a more aggressive learning process.
Regularization: XGBoost applies regularization techniques such as L1 and L2 regularization to control the complexity of the ensemble and prevent overfitting. Regularization terms are included in the objective function, encouraging simpler models.
Prediction: To make predictions, XGBoost combines the predictions of all weak models in the ensemble. The final prediction is the weighted sum of the individual predictions, where each weak model's contribution is determined by its performance and the learning rate.
By iteratively adding new models that focus on correcting the mistakes of previous models, XGBoost builds a strong and accurate ensemble that can generalize well to new data. The combination of gradient descent optimization, weighted updates, regularization, and learning rate control allows XGBoost to efficiently learn complex patterns and improve predictive modeling performance.
What are the advantages of using XGBoost over other machine learning algorithms?
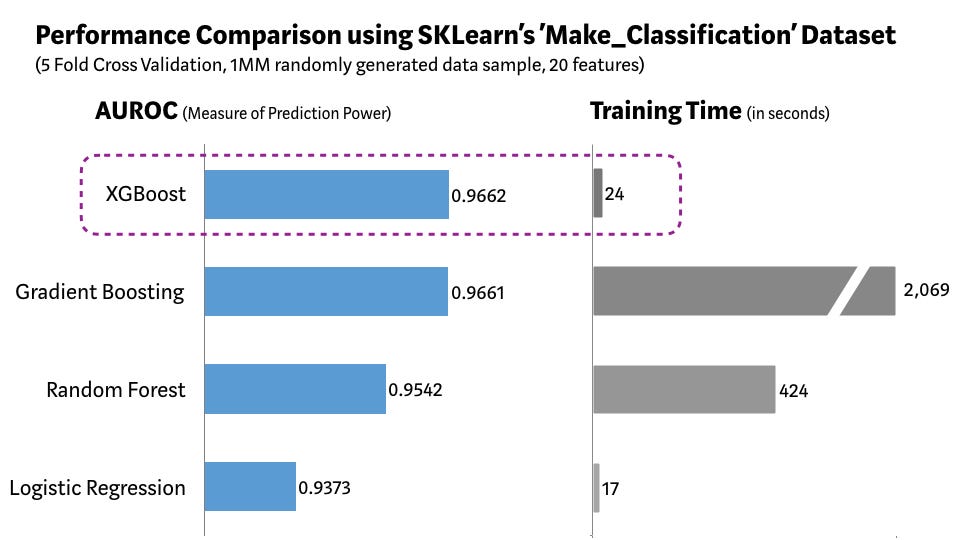
High Performance: XGBoost is known for its exceptional performance and speed. It is optimized to handle large-scale datasets efficiently, making it faster than many other algorithms.
Scalability: XGBoost is designed to scale horizontally, making it suitable for handling big data. It leverages parallelization techniques to take advantage of multi-core processors and distributed computing frameworks.
Flexibility: XGBoost can handle a wide range of data types, including numerical and categorical features. It supports both regression and classification tasks, making it versatile for various predictive modeling problems.
Robustness to Overfitting: XGBoost incorporates regularization techniques such as L1 and L2 regularization, which help prevent overfitting and improve the generalization ability of the model.
Handling Missing Values: XGBoost has built-in capabilities to handle missing values in the dataset. It automatically learns the best direction to handle missing values during the tree construction process, eliminating the need for manual imputation or preprocessing steps.
Feature Importance: XGBoost provides built-in feature selection capabilities and allows for the assessment of feature importance. It ranks the importance of features based on their contribution to the model's performance, aiding in feature engineering and understanding the underlying patterns.
Optimized Tree Construction: XGBoost utilizes an optimized algorithm for tree construction. It employs approximate tree learning techniques, such as quantile sketching and gradient statistics, to find optimal splits efficiently, resulting in faster and more accurate tree building.
Regularized Learning Objective: XGBoost offers a variety of loss functions and a customizable learning objective. This allows users to define their specific objectives and tailor the algorithm to their specific problem domain.
Early Stopping: XGBoost includes early stopping functionality, which enables automatic stopping of the training process when the model's performance on a validation set does not improve, preventing overfitting and saving computation time.
Active Community and Industry Adoption: XGBoost has gained significant popularity and has a vibrant community. It is widely adopted in both academia and industry, with extensive resources, tutorials, and support available.
What regularization techniques are employed in XGBoost to prevent overfitting?
XGBoost (eXtreme Gradient Boosting) employs various regularization techniques to prevent overfitting and enhance the generalization ability of the model. The key regularization techniques used in XGBoost are:
Shrinkage/learning rate (eta): The shrinkage parameter controls the learning rate of the boosting process. By reducing the contribution of each individual weak learner (tree) added to the ensemble, it makes the learning process more conservative and helps prevent overfitting.
Tree Complexity Control: XGBoost includes parameters to control the complexity of the individual trees in the ensemble, such as:
Max Depth: Limits the maximum depth of each tree, preventing them from growing too deep and capturing noisy or irrelevant patterns.
Min Child Weight: Specifies the minimum sum of instance weights required in a child node. It acts as a threshold to prevent further partitioning of nodes with low weights, which helps reduce overfitting.
Gamma: The gamma parameter specifies the minimum loss reduction required to make a further partition on a leaf node of the tree. It controls the complexity of the trees by penalizing splits that do not significantly reduce the loss. Higher gamma values result in more conservative tree growth.
Subsampling: XGBoost allows subsampling of the training instances (rows) and features (columns) in each iteration. These parameters, namely subsample and colsample_bytree, control the fraction of data and features to be randomly selected. Subsampling can help reduce overfitting by introducing randomness and diversity into the ensemble.
Regularization Terms: XGBoost incorporates L1 (Lasso) and L2 (Ridge) regularization terms in the objective function. These terms add penalties to the complexity of the model by adding the absolute values of the weights (L1) or the squared values of the weights (L2) to the loss function. They encourage sparsity and shrink the magnitude of the weights, respectively, reducing overfitting.
Early Stopping: XGBoost implements early stopping functionality, which monitors the performance on a validation set during the training process. If the performance does not improve for a certain number of iterations (defined by the early stopping parameters), the training is stopped early to prevent overfitting and save computational resources.
How does XGBoost handle missing values in the dataset?
Learning Direction for Missing Values: XGBoost automatically learns the best direction to handle missing values during the tree construction process. It does this by analyzing the distribution of the available data and deciding whether to assign missing values to the left or right child of each tree node. This allows XGBoost to utilize the available information effectively.
Missing Values as a Separate Category: XGBoost treats missing values as a separate category or branch in the tree structure. When building the trees, it can create a dedicated child node for missing values, allowing them to be handled explicitly.
Splits Involving Missing Values: XGBoost can handle splits involving missing values in a flexible manner. It can evaluate whether a data point has a missing value and navigate the tree structure accordingly, determining which child node to follow based on the presence or absence of the feature value.
Imputation of Missing Values: XGBoost does not require explicit imputation or preprocessing of missing values before training. Instead, it can automatically incorporate missing values during the tree building process without the need for imputation techniques such as mean, median, or mode imputation.
It's important to note that while XGBoost can handle missing values, it is still recommended to carefully analyze the nature and patterns of missing values in the dataset. Missing values may contain valuable information, and imputation or other preprocessing techniques might be necessary depending on the specific problem and data characteristics.
Can you briefly explain the objective functions available in XGBoost for regression and classification tasks?
Regression Objective Functions:
Squared Loss: The squared loss (reg:squarederror) is the default objective function for regression in XGBoost. It minimizes the sum of squared differences between the predicted and actual values.
Absolute Loss: The absolute loss (reg:linear) minimizes the sum of absolute differences between the predicted and actual values. It is less sensitive to outliers compared to squared loss.
Huber Loss: The Huber loss (reg:huber) is a combination of the squared and absolute loss functions. It provides robustness to outliers by using a different loss calculation for smaller and larger errors.
Gamma Loss: The gamma loss (reg:gamma) is suitable for modeling the gamma distribution, often used for modeling non-negative continuous variables.
Tweedie Loss: The Tweedie loss (reg:tweedie) is designed for modeling data with a Tweedie compound Poisson distribution, which covers a wide range of continuous distributions including normal, gamma, and Poisson.
Classification Objective Functions:
Logistic Loss: The logistic loss (binary:logistic) is the default objective function for binary classification in XGBoost. It optimizes the logistic loss, which is suitable for binary classification problems where the predicted values are probabilities.
Binary Classification Error: The binary classification error (binary:logitraw) minimizes the classification error rate directly.
Multiclass Classification: XGBoost supports several objective functions for multiclass classification, such as softmax (multi:softmax), which applies the softmax function to the predicted values, and multiclass logistic loss (multi:softprob), which optimizes the log loss for multiclass classification.
What is the role of the learning rate (eta) parameter in XGBoost, and how does it affect the training process?
Control over Model Updates: The learning rate controls the magnitude of updates applied to the model's weights during each iteration. A lower learning rate results in smaller updates, making the learning process more conservative, while a higher learning rate leads to more aggressive updates.
Trade-off between Stability and Learning Speed: The learning rate provides a trade-off between the stability and learning speed of the model. A lower learning rate makes the training more stable but slower, as each individual weak learner has a smaller impact on the ensemble. Conversely, a higher learning rate speeds up the learning process but may result in more oscillations and instability.
Regularization Effect: The learning rate acts as a form of regularization. By reducing the contribution of each individual tree to the ensemble, it helps prevent overfitting and improves the generalization ability of the model. It encourages the model to rely on a larger number of weak learners, reducing the risk of over-reliance on a few strong learners.
Need for Tuning: The learning rate is an important hyperparameter that needs to be tuned. It must be carefully chosen to balance the learning speed, stability, and generalization performance of the model. Typically, a lower learning rate requires a higher number of iterations (trees) to achieve optimal performance, while a higher learning rate may lead to faster convergence but with a higher risk of overfitting.
Ensemble of Learning Rates: XGBoost employs a strategy called boosting, where new weak learners are added to the ensemble to correct the mistakes of previous models. The learning rate allows each new weak learner to have a specific weight or influence on the ensemble. The final prediction is a weighted sum of the predictions from all weak learners, where the learning rate determines the contribution of each learner.
Describe the process of early stopping in XGBoost and its purpose.
Early stopping is a technique used in XGBoost (eXtreme Gradient Boosting) to prevent overfitting and determine the optimal number of boosting iterations (trees) during the training process. The process of early stopping involves monitoring the performance of the model on a separate validation set and stopping the training when the performance no longer improves. Here's how early stopping works in XGBoost:
Training and Validation Sets: The dataset is split into training and validation sets. The training set is used to build the boosting model, while the validation set is used to monitor the model's performance during the training process.
Evaluation Metric: An evaluation metric is chosen to measure the model's performance on the validation set. Common evaluation metrics include mean squared error (MSE) for regression tasks or accuracy, precision, recall, or F1-score for classification tasks.
Training Iterations: XGBoost starts the training process by iteratively adding weak learners (trees) to the ensemble. After each iteration, the model's performance is evaluated on the validation set using the chosen evaluation metric.
Early Stopping Condition: XGBoost continuously monitors the performance on the validation set. If the performance does not improve after a certain number of iterations or fails to meet a predefined improvement threshold, the early stopping condition is triggered.
Stopping and Final Model: When the early stopping condition is met, the training process is stopped, and the model at that iteration is considered the final model. It is selected based on the point where the performance on the validation set was the best.
How does XGBoost handle categorical variables in the dataset?
One-Hot Encoding: By default, XGBoost does not handle categorical variables directly. Therefore, the categorical variables need to be one-hot encoded before feeding them into the algorithm. One-hot encoding represents each category as a binary feature, where each feature corresponds to a unique category, and its value is 1 if the original variable belongs to that category and 0 otherwise.
Sparse Matrix Support: XGBoost efficiently handles sparse matrices, which can be beneficial when dealing with high-dimensional one-hot encoded categorical features. Sparse matrices store only non-zero elements, saving memory and computational resources.
Column Sampling: XGBoost offers a feature called "colsample_bytree" that allows you to specify the fraction of features (columns) to be randomly sampled at each tree construction. This feature can help reduce the dimensionality and speed up the training process, especially when dealing with a large number of categorical variables.
Built-in Missing Value Handling: XGBoost has built-in capabilities to handle missing values. For categorical variables, XGBoost can handle missing values by assigning them a default direction during the tree construction process, similar to how it handles missing values for numerical variables.
Learning-Based Handling (Experimental): XGBoost has recently introduced an experimental feature called "Learning-to-Rank" that enables learning-based handling of categorical variables. This feature allows XGBoost to learn the best split decisions for categorical variables directly from the data, rather than relying on one-hot encoding.
What are the key hyperparameters in XGBoost, and how do they impact the model's performance?
Learning Rate (eta): The learning rate controls the step size or shrinkage rate of the updates made to the model's weights in each boosting iteration. A lower learning rate makes the training process more conservative but slower, while a higher learning rate leads to faster convergence but may result in overfitting if not properly tuned.
Number of Trees (n_estimators): It represents the number of boosting iterations (trees) to be built. Increasing the number of trees generally improves the model's performance, but it comes with a trade-off in terms of computational cost. Adding too many trees can lead to overfitting, so it needs to be carefully chosen through techniques like cross-validation.
Tree Depth (max_depth): This parameter controls the maximum depth of each individual tree in the ensemble. A deeper tree can capture more complex interactions but is more prone to overfitting. It is essential to set an appropriate maximum depth based on the complexity of the problem and the dataset.
Minimum Child Weight (min_child_weight): It specifies the minimum sum of instance weights required to create a new split in a tree. Higher values enforce more conservative tree growth by preventing further partitioning of nodes with low weights. It helps control overfitting and is particularly useful when dealing with imbalanced datasets.
Subsampling (subsample): It determines the fraction of training instances (rows) to be randomly sampled for each tree construction iteration. Subsampling introduces randomness and diversity into the ensemble, which can reduce overfitting. However, setting a value too low may lead to underfitting, while a value too high may result in overfitting.
Column Subsampling by Tree (colsample_bytree): It specifies the fraction of features (columns) to be randomly selected at each tree construction iteration. Similar to subsampling, it introduces randomness and reduces the risk of overfitting. It is particularly useful when dealing with high-dimensional datasets with many features.
Regularization Parameters (lambda and alpha): Lambda (L2 regularization) and alpha (L1 regularization) control the amount of regularization applied to the weights of the model. They help prevent overfitting by adding penalties to the complexity of the model. Lambda encourages weights to be smaller, while alpha encourages sparsity by driving some weights to zero.
Early Stopping (early_stopping_rounds): This parameter enables early stopping functionality, allowing the training process to stop if the performance on the validation set does not improve for a specified number of iterations. It helps prevent overfitting and saves computational resources.
How can you assess the importance of features in an XGBoost model?
Feature Importance Plot: XGBoost offers a built-in feature importance plot that ranks features based on their importance score. The importance score reflects the number of times a feature is used to split across all the trees in the model. The higher the score, the more important the feature. This plot provides a quick visual overview of feature importance.
Feature Importance Values: XGBoost provides access to the feature importance values, which can be obtained programmatically. The importance values represent the average gain of each feature over all the trees in the ensemble. Higher values indicate greater importance.
Gini Importance: XGBoost can calculate the Gini importance, which is based on the total reduction of the Gini impurity criterion achieved by a feature across all the trees. Features with higher Gini importance are considered more important.
Permutation Importance: Permutation importance is a technique that involves randomly permuting the values of a single feature and measuring the resulting impact on the model's performance. XGBoost allows you to calculate permutation importance by evaluating the change in evaluation metric (e.g., accuracy or mean squared error) when a feature's values are permuted. A greater decrease in performance indicates higher importance.
SHAP Values: SHAP (SHapley Additive exPlanations) values provide a unified approach to interpret the impact of each feature on individual predictions. XGBoost can generate SHAP values that represent the contribution of each feature for each instance. Aggregating these values across the dataset helps assess the global importance of features.
What is the difference between XGBoost's tree-based and linear base learners?
Tree-Based Base Learners: Tree-based base learners are decision trees, which are the default choice in XGBoost. These base learners are composed of nodes and branches that make hierarchical splits based on feature values. Each leaf node represents a prediction. Tree-based base learners have the following characteristics:
They can model complex nonlinear relationships between features and the target variable.
They handle both numerical and categorical features by making binary splits.
They can capture feature interactions and non-linear patterns in the data.
They are prone to overfitting if not properly regularized.
Linear Base Learners: Linear base learners represent a linear model, where the prediction is a linear combination of the input features. These base learners have the following characteristics:
They model linear relationships between features and the target variable.
They are useful when the relationships between features and the target are primarily linear.
They are less flexible in capturing complex nonlinear patterns.
They are less prone to overfitting due to their inherent linearity.
They can handle high-dimensional datasets more efficiently.
The choice between tree-based and linear base learners depends on the nature of the data and the problem at hand. Tree-based base learners are generally more flexible and can capture complex relationships, making them suitable for a wide range of tasks. However, they may require careful tuning to prevent overfitting. On the other hand, linear base learners are more interpretable and efficient for high-dimensional datasets with linear relationships. XGBoost allows you to specify the base learner type based on the specific requirements of your problem.
Explain the concept of ensemble learning and how it is utilized in XGBoost.
Boosting: XGBoost is based on the boosting framework, which involves sequentially adding weak learners (base models) to an ensemble. Each weak learner is trained to correct the mistakes made by the previous learners. In XGBoost, the weak learners are decision trees, either tree-based or linear.
Gradient Boosting: XGBoost uses gradient boosting, where the weak learners are added to the ensemble in a stage-wise manner. The subsequent weak learners are trained to minimize the errors (residuals) of the previous learners. This gradient-based approach allows XGBoost to focus on the samples that are challenging to predict, improving the overall model performance.
Weighted Voting: XGBoost assigns weights to each weak learner based on its performance and contribution to the ensemble. The weights reflect the importance of each learner's predictions when making the final prediction. Weak learners that perform well and have low errors are given higher weights, while those with higher errors receive lower weights.
Regularization and Control: XGBoost applies regularization techniques to control the complexity and overfitting of the ensemble. Regularization parameters, such as lambda (L2 regularization) and alpha (L1 regularization), are used to add penalties to the complexity of the model. Regularization helps prevent overfitting and improves the generalization ability of the ensemble.
Combining Predictions: The final prediction in XGBoost is made by combining the predictions of all the weak learners in the ensemble, weighted by their respective weights. The combination can be a simple average, weighted average, or other techniques based on the specific task (regression or classification).
By utilizing ensemble learning through gradient boosting, XGBoost improves the performance and robustness of predictions. It combines multiple weak learners to create a strong ensemble that can handle complex relationships, capture non-linear patterns, and achieve better accuracy compared to individual models. The sequential training and weighted voting process in XGBoost ensure that the ensemble learns from previous mistakes and focuses on challenging samples, enhancing the overall predictive power of the model.
How can you tune the hyperparameters of an XGBoost model to improve its performance?
Start with Default Parameters: Begin by using the default parameters of XGBoost, as they are often a good starting point and can yield reasonable results.
Define Evaluation Metrics: Clearly define the evaluation metrics that align with your problem, such as mean squared error (MSE) for regression or accuracy for classification. These metrics will guide the hyperparameter tuning process.
Grid Search: Perform a grid search by defining a set of possible values for each hyperparameter of interest. Train and evaluate the XGBoost model using each combination of hyperparameters and select the one that gives the best performance. Grid search is an exhaustive but computationally expensive approach.
Random Search: Alternatively, use random search to randomly sample combinations of hyperparameters within predefined ranges. This approach can be more efficient than grid search, especially when the search space is large.
Cross-Validation: Perform cross-validation to assess the performance of different hyperparameter configurations. Split your training data into multiple folds, train and evaluate the XGBoost model on each fold, and average the results. This helps to reduce the impact of randomness and provide a more reliable estimate of performance.
Early Stopping: Utilize early stopping to prevent overfitting and save computational resources. Monitor the performance of the model on a validation set during training and stop the training process if the performance does not improve for a certain number of iterations.
Learning Rate and Number of Trees: Experiment with the learning rate (eta) and number of trees (n_estimators) as they significantly impact the model. Lower learning rates and higher numbers of trees can improve accuracy but require more computational resources.
Regularization Parameters: Tune the regularization parameters, lambda (L2 regularization) and alpha (L1 regularization), to control the complexity of the model and prevent overfitting. Higher values of lambda and alpha increase the regularization strength.
Feature Importance: Assess the feature importance provided by XGBoost to identify and prioritize the most influential features. Consider removing irrelevant or redundant features to simplify the model.
Iterative Process: Hyperparameter tuning is an iterative process. Experiment with different combinations, evaluate the performance, and fine-tune the parameters based on the results. It may require multiple iterations to find the optimal hyperparameters.
Can you compare XGBoost with Random Forest and highlight their differences and similarities?
Differences:
Algorithm Type: XGBoost is a boosting algorithm, while Random Forest is an ensemble algorithm.
Training Approach: XGBoost builds trees sequentially, optimizing the objective function through gradient-based boosting, while Random Forest builds trees independently using bootstrap aggregating (bagging).
Handling of Missing Values: XGBoost has built-in capability to handle missing values, while Random Forest can only handle missing values by imputation or exclusion.
Feature Subsets: Random Forest selects a random subset of features at each split, whereas XGBoost considers all features for each split and utilizes feature importance for selection.
Complexity: XGBoost can capture complex relationships and interactions in the data, while Random Forest typically handles simpler relationships between features and the target variable.
Similarities:
Ensemble Learning: Both XGBoost and Random Forest utilize ensemble learning techniques to combine multiple weak learners (trees) to make predictions.
Handling of Categorical Variables: Both algorithms can handle categorical variables directly, converting them into numerical representations suitable for tree-based models.
Regularization: XGBoost and Random Forest offer options for regularization to prevent overfitting. XGBoost has regularization parameters like lambda and alpha, while Random Forest uses techniques like maximum tree depth and minimum sample split.
Feature Importance: Both XGBoost and Random Forest provide measures of feature importance, which can help identify the most influential features in the model.
What are some potential limitations or challenges when working with XGBoost?
Computational Complexity: XGBoost can be computationally expensive, especially when dealing with large datasets or complex models with a large number of trees and high-dimensional feature spaces. Training time and memory usage can become significant challenges.
Hyperparameter Tuning: XGBoost has several hyperparameters that need to be tuned, such as learning rate, tree depth, number of trees, regularization parameters, and more. Finding the optimal combination of hyperparameters requires experimentation and can be time-consuming.
Data Preprocessing: XGBoost does not handle categorical variables directly. They need to be preprocessed and converted into numerical representations, which may require additional effort and consideration.
Feature Engineering: The performance of XGBoost heavily relies on the quality of the features. Feature engineering, including feature selection, transformation, and creation, is crucial for obtaining meaningful and informative features.
Sensitive to Outliers: XGBoost can be sensitive to outliers, as the algorithm tries to minimize the loss function. Outliers can disproportionately affect the model's training process and lead to suboptimal results. Proper handling of outliers is essential.
Imbalanced Data: XGBoost may struggle with imbalanced datasets, where one class significantly outweighs the others. It requires careful consideration of techniques such as class weighting, oversampling, or undersampling to address the class imbalance issue.
Interpretability: While XGBoost provides feature importance measures, the overall model interpretability can be challenging due to its complex ensemble nature. Understanding the relationships between features and predictions can be difficult compared to simpler models like linear regression.
Limited Handling of Text and Image Data: XGBoost is primarily designed for structured data and may not be the best choice for tasks involving unstructured data such as text or image analysis. Specialized models or preprocessing techniques may be required for such data types.
How can you interpret the output of an XGBoost model in terms of feature importance?
Gain Importance: XGBoost calculates feature importance based on the average gain of each feature across all splits in the trees. The gain represents the improvement in the objective function (e.g., reduction in training loss) achieved by a particular feature when it is chosen for splitting. Higher gain values indicate more important features.
Plotting Feature Importance: XGBoost provides a built-in method to plot the feature importance. By using the
plot_importance()function, you can generate a bar plot showing the relative importance of each feature. The plot is usually sorted in descending order of importance.Quantitative Importance Measures: XGBoost assigns an importance score to each feature, which represents the relative importance compared to the sum of all feature importance scores. This score can be accessed through the
feature_importances_attribute of the trained XGBoost model. You can retrieve the importance scores and use them for further analysis or ranking the features.Feature Selection: Feature importance can guide feature selection or dimensionality reduction. By considering the most important features and discarding less relevant ones, you can simplify the model, improve its interpretability, and potentially reduce overfitting.
Contextual Interpretation: Remember that feature importance is relative to the other features within the model. It is important to interpret feature importance in the context of the specific problem and dataset. A feature may have high importance in one model but lower importance when combined with other features in a different model.
Domain Knowledge: While feature importance provides valuable insights, it is essential to combine it with domain knowledge and understanding of the data. Some features may have high importance due to their correlation with the target variable, but their practical significance or causal relationship may need further investigation.
Are there any specific scenarios or types of data where XGBoost is particularly effective or not suitable?
Scenarios where XGBoost is particularly effective:
Tabular Data: XGBoost is highly effective for structured/tabular data where the features are well-defined and have clear relationships with the target variable. It excels in problems such as regression, classification, and ranking tasks.
Large and Complex Datasets: XGBoost can handle large datasets with high dimensionality and a large number of features. It can capture complex relationships and interactions between features, making it suitable for challenging and diverse datasets.
Imbalanced Data: XGBoost provides options to address class imbalance, such as weighted loss functions or subsampling, making it effective in handling imbalanced datasets where one class is underrepresented.
Feature Importance: XGBoost's ability to provide feature importance measures helps identify the most influential features in the model. This can be beneficial in feature selection, feature engineering, and gaining insights into the underlying data.
Ensemble Learning: XGBoost's boosting framework allows it to build strong ensemble models by combining multiple weak learners. This makes it particularly effective in improving model performance and generalization.
Scenarios where XGBoost may be less suitable:
Text and Image Data: XGBoost is primarily designed for structured data and may not be the best choice for unstructured data such as text or image analysis. Specialized models or preprocessing techniques like NLP or CNNs are often more suitable for these types of data.
Small Datasets: XGBoost's power comes from the ability to capture complex patterns and interactions, but it requires a sufficient amount of data to generalize well. When dealing with small datasets, XGBoost may be prone to overfitting, and simpler models or techniques like regularization may be more appropriate.
Real-time Predictions: XGBoost can be computationally expensive, especially when dealing with large models or complex datasets. In scenarios where real-time predictions are required, the model's computational requirements may be a limitation.
Highly Noisy Data: XGBoost is sensitive to noisy data or outliers. If the dataset contains a significant amount of noise, extreme outliers, or erroneous observations, it may impact the model's performance.
What are some practical considerations for implementing XGBoost in a production environment?
Data Preprocessing: Ensure that the data preprocessing steps used during training are applied consistently in the production environment. This includes handling missing values, encoding categorical variables, scaling or normalizing features, and any other necessary data transformations.
Feature Engineering: Pay attention to feature engineering techniques used during model development. It's crucial to maintain consistency in feature engineering between training and production to ensure accurate predictions. Any new features or feature modifications should be applied consistently.
Model Deployment: Decide on an appropriate method to deploy the trained XGBoost model in the production environment. This can include options such as deploying as a REST API, embedding it within an application, or utilizing a model serving infrastructure like TensorFlow Serving or SageMaker.
Scalability and Performance: Consider the scalability and performance requirements of the production system. XGBoost can be computationally expensive, especially with large models or high-throughput prediction scenarios. Ensure that the production environment has sufficient computational resources to handle the workload efficiently.
Monitoring and Versioning: Implement mechanisms to monitor the performance of the deployed XGBoost model. This includes tracking prediction accuracy, monitoring prediction latency, and logging model outputs for analysis. Additionally, establish version control to keep track of different model versions and facilitate model rollback or comparison.
Updating and Retraining: Determine a strategy for updating and retraining the XGBoost model as new data becomes available or the model performance degrades. Establish a process to periodically evaluate model performance, monitor data drift, and trigger model retraining or updates when necessary.
Error Handling and Robustness: Implement proper error handling and exception management mechanisms in the production system. This includes handling potential issues such as missing or invalid inputs, network failures, or model-related errors. Ensure that the system gracefully handles these scenarios and provides appropriate feedback or fallback options.
Security and Privacy: Consider security and privacy aspects when implementing XGBoost in a production environment. Protect sensitive data, ensure secure communication channels, and comply with privacy regulations and best practices.
Documentation and Collaboration: Document the implementation process, including data preprocessing steps, model configuration, and deployment details. Foster collaboration and communication among data scientists, developers, and stakeholders involved in the production pipeline.
What are the differences between XGBoost and LightGBM?
Algorithmic approach: XGBoost uses a pre-sort-based algorithm, where the dataset is sorted based on feature values to find optimal split points. In contrast, LightGBM uses a histogram-based algorithm, constructing histograms of feature values to efficiently find split points. This difference affects computational efficiency and memory usage.
Handling of categorical features: LightGBM has built-in support for handling categorical features, while XGBoost requires one-hot encoding or other methods to encode categorical variables. LightGBM can directly work with categorical features by partitioning them in the histogram construction process, which is more convenient and efficient.
Data parallelism: LightGBM employs data parallelism, where different machines or threads handle different data partitions simultaneously. This parallelization strategy improves training speed, especially for large datasets. On the other hand, XGBoost focuses on feature parallelism, where each machine or thread handles a subset of features during training.
Memory usage: LightGBM is designed to be memory-efficient. Its histogram-based algorithm and data partitioning techniques enable it to use less memory compared to XGBoost, especially for large datasets or datasets with many features.
Performance: XGBoost and LightGBM have shown competitive performance in various machine learning tasks. However, their differences in algorithmic approaches, handling of categorical features, parallelization strategies, and memory usage make one framework potentially more suitable than the other depending on the specific dataset and problem.
Python Implement
Using Sklearn
x531import numpy as np2from sklearn.datasets import load_iris3from sklearn.model_selection import train_test_split, GridSearchCV4from sklearn.metrics import accuracy_score5import xgboost as xgb6
7# Load the Iris dataset8iris = load_iris()9X = iris.data10y = iris.target11
12# Split the dataset into training and testing sets13X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)14
15# Convert the data into DMatrix format for XGBoost16dtrain = xgb.DMatrix(X_train, label=y_train)17dtest = xgb.DMatrix(X_test, label=y_test)18
19# Set the parameters for XGBoost20params = {21 'objective': 'multi:softmax',22 'num_class': 3,23 'max_depth': 3,24 'eta': 0.1,25 'eval_metric': 'merror'26}27
28# Define the range of hyperparameters to search29param_grid = {30 'max_depth': [3, 5, 7],31 'eta': [0.1, 0.01, 0.001],32 'min_child_weight': [1, 3, 5]33}34
35# Perform grid search to find the best hyperparameters36grid_search = GridSearchCV(estimator=xgb.XGBClassifier(**params), param_grid=param_grid, cv=5)37grid_search.fit(X_train, y_train)38
39# Get the best hyperparameters40best_params = grid_search.best_params_41print("Best Hyperparameters:", best_params)42
43# Train the XGBoost model with the best hyperparameters44num_rounds = 10045model = xgb.train(best_params, dtrain, num_rounds)46
47# Make predictions on the test set48predictions = model.predict(dtest)49
50# Evaluate the accuracy of the model51accuracy = accuracy_score(y_test, predictions)52print("Accuracy:", accuracy)In this example, we added the hyperparameter tuning process using GridSearchCV from scikit-learn. We define a grid of hyperparameters to search through, including max_depth, eta, and min_child_weight. The cv parameter in GridSearchCV specifies the number of cross-validation folds.
We perform a grid search using fit() to find the best hyperparameters for the XGBoost model. The best hyperparameters are obtained using best_params_ attribute.
Next, we train the XGBoost model with the best hyperparameters using xgb.train(). The remaining steps for making predictions and evaluating the accuracy of the model remain the same.
How to Train XGBoost Model With PySpark
xxxxxxxxxx1431# Step 1: Install the necessary libraries2!pip install sparkxgb3
4# Step 2: Import the necessary modules5from sparkxgb import XGBoostClassifier, XGBoostRegressor6from pyspark.ml.evaluation import BinaryClassificationEvaluator, RegressionEvaluator7from pyspark.ml import Pipeline8
9# Step 3: Create a PySpark DataFrame10# Assuming you have already loaded your data into a DataFrame called 'data'11
12# Step 4: Split the data into training and test sets13train_data, test_data = data.randomSplit([0.8, 0.2], seed=42)14
15# Step 5: Define the XGBoost model16xgb_model = XGBoostClassifier(17 featuresCol='features',18 labelCol='label',19 objective='binary:logistic',20 numRound=100,21 earlyStoppingRound=10,22 evalMetric='auc'23)24
25# Step 6: Create a pipeline26pipeline = Pipeline(stages=[xgb_model])27
28# Step 7: Fit the pipeline29model = pipeline.fit(train_data)30
31# Step 8: Make predictions32predictions = model.transform(test_data)33
34# Step 9: Evaluate the model35evaluator = BinaryClassificationEvaluator()36auc = evaluator.evaluate(predictions)37print('AUC:', auc)38
39# For regression, use the following evaluation code instead:40# evaluator = RegressionEvaluator()41# rmse = evaluator.evaluate(predictions, {evaluator.metricName: 'rmse'})42# print('RMSE:', rmse)