Adaboost
AdaboostSummaryKey takeawaysInterview QuestionsWhat is AdaBoost and how does it work?What are the main advantages of using AdaBoost in comparison to other ensemble methods?Can you explain the concept of weak learners in the context of AdaBoost?How does AdaBoost handle misclassified samples during the training process? What is the role of the weighting factor in AdaBoost?Are there any limitations or potential drawbacks of using AdaBoost?How do you choose the appropriate number of iterations (boosting rounds) in AdaBoost?Can you briefly describe the AdaBoost algorithm in pseudocode or step-by-step?How can you handle class imbalance using AdaBoost?Are there any variations or extensions of AdaBoost that you are familiar with?Python ApplicationAdaBoostClassifier()
Summary
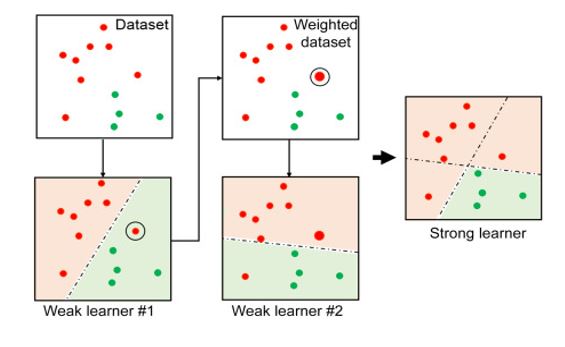
AdaBoost is an ensemble learning algorithm that combines multiple weak learners in a sequential manner, assigning higher weights to misclassified instances, to create a strong classifier.
Key takeaways
AdaBoost is a boosting algorithm that combines multiple weak learners to create a strong classifier.
The weak learners in AdaBoost are typically decision stumps, which are shallow decision trees with only one split.
AdaBoost assigns weights to each training example, initially setting them to equal values. It then iteratively trains weak learners on the weighted examples, giving more emphasis to misclassified examples.
Each weak learner is trained on a modified version of the training data, where the weights of the misclassified examples are increased. This focuses the subsequent weak learners on the previously misclassified examples.
AdaBoost combines the weak learners by assigning weights to their predictions based on their performance. Better-performing weak learners are given higher weights.
During the final classification, the predictions of all weak learners are combined, and the class with the highest weighted vote is selected as the final prediction.
AdaBoost is an adaptive algorithm, meaning it adjusts its weights and focuses on difficult examples during training.
AdaBoost is effective in handling complex classification problems and can achieve high accuracy by combining weak learners.
AdaBoost is sensitive to noisy data and outliers, as they can have a large influence on the training process.
AdaBoost has been widely used in various applications, including face detection, object recognition, and natural language processing. It has also inspired the development of other boosting algorithms.
Interview Questions
What is AdaBoost and how does it work?
AdaBoost, short for Adaptive Boosting, is a popular ensemble learning algorithm that combines multiple weak learners to create a strong learner. It works by iteratively training weak classifiers on different subsets of the training data.
During each iteration, the algorithm assigns higher weights to misclassified samples from previous iterations, thereby focusing on the harder-to-classify examples. The final prediction is made by aggregating the predictions of all weak learners, weighted by their individual performance.
What are the main advantages of using AdaBoost in comparison to other ensemble methods?
The main advantages of using AdaBoost compared to other ensemble methods include:
High accuracy: AdaBoost can achieve higher accuracy than individual weak learners by combining their predictions effectively.
Handling complex datasets: AdaBoost is capable of handling complex datasets with overlapping or non-linear decision boundaries.
Feature selection: AdaBoost implicitly performs feature selection by assigning higher importance to informative features.
Reduced risk of overfitting: The iterative nature of AdaBoost with adaptive sample weighting helps prevent overfitting and generalizes well to unseen data.
Versatility: AdaBoost can be used with various weak learning algorithms, such as decision trees, to build a diverse ensemble.
Can you explain the concept of weak learners in the context of AdaBoost?
In the context of AdaBoost, weak learners refer to simple models or classifiers that perform slightly better than random guessing. They are typically simple decision rules or classifiers with low complexity, such as decision stumps (decision trees with a single split). These weak learners are combined to form a strong ensemble model through boosting.
How does AdaBoost handle misclassified samples during the training process?
AdaBoost handles misclassified samples by assigning higher weights to these samples in subsequent iterations. In each iteration, the algorithm focuses more on the misclassified samples, allowing the subsequent weak learners to learn from the mistakes of the previous learners. By assigning higher weights to the misclassified samples, AdaBoost forces the subsequent weak learners to pay more attention to those samples and adjust their predictions accordingly. This iterative process gradually improves the model's ability to correctly classify the difficult examples.
What is the role of the weighting factor in AdaBoost?
The weighting factor in AdaBoost determines the importance or influence of each weak learner in the ensemble. Initially, all samples in the training set have equal weights. However, as the iterations progress, AdaBoost assigns higher weights to misclassified samples from previous iterations. These weights affect the training process by emphasizing the importance of misclassified samples, thereby making subsequent weak learners focus more on these challenging examples. The weighting factor influences how much each weak learner contributes to the final ensemble prediction, with more weight given to more accurate classifiers.
Are there any limitations or potential drawbacks of using AdaBoost?
Sensitivity to outliers: AdaBoost can be sensitive to outliers in the training data, which may affect the performance of the ensemble by influencing the weighting of misclassified samples.
Computationally expensive: AdaBoost can be computationally expensive, particularly when dealing with large datasets or complex weak learners, as it requires iteratively training multiple models.
Noisy data impact: AdaBoost's performance can be affected by noisy data, as it assigns higher weights to misclassified samples, potentially leading to overfitting.
How do you choose the appropriate number of iterations (boosting rounds) in AdaBoost?
Choosing the appropriate number of iterations (boosting rounds) in AdaBoost: The appropriate number of iterations in AdaBoost is typically determined using cross-validation or a validation set. The algorithm is trained with different numbers of boosting rounds, and the performance is evaluated on a separate validation set. The number of iterations is chosen where the performance on the validation set starts to plateau or when further iterations do not significantly improve the performance.
Can you briefly describe the AdaBoost algorithm in pseudocode or step-by-step?
xxxxxxxxxx171Input: Training dataset D = {(x1, y1), (x2, y2), ..., (xn, yn)}, where xi is the i-th training instance and yi is its corresponding label.2Output: Ensemble classifier H(x).3
41. Initialize the sample weights: w_i = 1 / n, where n is the number of training instances.5
62. For t = 1 to T (the desired number of iterations):7 a. Train a weak learner using the weighted training data. The weak learner aims to minimize the weighted error.8 b. Calculate the weighted error of the weak learner: ε_t = sum(w_i * (1 if h_t(xi) != yi else 0) / sum(w_i)), where h_t(xi) is the prediction of the weak learner on instance xi.9 c. Calculate the weight of the weak learner: α_t = 0.5 * log((1 - ε_t) / ε_t).10 d. Update the sample weights:11 - For each training instance i:12 - If h_t(xi) == yi, w_i = w_i * exp(-α_t).13 - If h_t(xi) != yi, w_i = w_i * exp(α_t).14 - Normalize the weights: w_i = w_i / sum(w_i).15
163. Output the ensemble classifier H(x) as the weighted combination of the weak learners:17 H(x) = sign(sum(α_t * h_t(x))).How can you handle class imbalance using AdaBoost?
AdaBoost can be used to handle class imbalance by adjusting the sample weights during the training process. Here's how class imbalance can be addressed using AdaBoost:
Initialize the sample weights: Set the initial weights for each training instance. For a balanced dataset, the weights are usually set to 1/N, where N is the total number of instances. In the case of class imbalance, assign higher weights to the minority class samples and lower weights to the majority class samples.
During each boosting round:
Train a weak learner on the weighted training set.
Calculate the weighted error rate of the weak learner on the training set, considering the sample weights.
Calculate the weight of the weak learner based on its performance. The weight is determined by how well the weak learner classified the instances, with higher weight assigned to more accurate classifiers.
Update the sample weights:
Increase the weights of misclassified instances, including those from the minority class, to make them more influential in subsequent iterations.
Decrease the weights of correctly classified instances, including those from the majority class, to reduce their influence.
The adjustment of weights ensures that the subsequent weak learners focus more on the misclassified instances, including those from the minority class.
Repeat the boosting rounds until the desired number of iterations is reached.
By adjusting the sample weights, AdaBoost places more emphasis on the misclassified instances, including those from the minority class. This allows the algorithm to concentrate on learning the patterns and boundaries of the minority class, improving its classification performance. Consequently, AdaBoost can handle class imbalance by giving more importance to the minority class during training.
Are there any variations or extensions of AdaBoost that you are familiar with?
Gradient Boosting: Gradient Boosting is a generalization of AdaBoost that uses gradient descent optimization to build an ensemble of weak learners. Instead of adjusting the sample weights, Gradient Boosting minimizes a loss function by iteratively adding weak learners that correct the residuals of the previous models.
XGBoost (Extreme Gradient Boosting): XGBoost is an optimized implementation of gradient boosting that incorporates additional features such as regularization techniques (e.g., L1 and L2 regularization), parallel processing, and tree pruning. It provides improved performance and scalability compared to traditional AdaBoost.
AdaBoost.M1: AdaBoost.M1 is the original AdaBoost algorithm designed for binary classification problems. It combines multiple weak learners to create a strong classifier.
AdaBoost.M2: AdaBoost.M2 extends AdaBoost to handle multiclass classification problems. It combines multiple binary classifiers in a one-vs-one or one-vs-all fashion to classify instances into multiple classes.
Real AdaBoost: Real AdaBoost is an extension of AdaBoost that deals with real-valued outputs instead of binary classification. It is suitable for tasks where the output labels have continuous or real values.
GentleBoost: GentleBoost is a modification of AdaBoost that uses exponential loss functions to handle noisy data more effectively. It gives lower weights to misclassified instances to mitigate the impact of noisy data.
Python Application
x
1from sklearn.datasets import load_iris2from sklearn.ensemble import AdaBoostClassifier3from sklearn.model_selection import train_test_split4from sklearn.metrics import accuracy_score5
6# Load the Iris dataset7iris = load_iris()8X = iris.data9y = iris.target10
11# Split the dataset into training and testing sets12X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)13
14# Create an AdaBoost classifier15adaboost = AdaBoostClassifier(n_estimators=50, random_state=42)16
17# Train the AdaBoost classifier18adaboost.fit(X_train, y_train)19
20# Make predictions on the test set21y_pred = adaboost.predict(X_test)22
23# Calculate the accuracy of the classifier24accuracy = accuracy_score(y_test, y_pred)25print("Accuracy:", accuracy)In this example, we first load the Iris dataset using the load_iris function from Scikit-learn. Then, we split the dataset into training and testing sets using the train_test_split function. We create an AdaBoost classifier with 50 estimators (weak learners) and fit it to the training data using the fit method. Next, we use the trained classifier to make predictions on the test set using the predict method. Finally, we calculate the accuracy of the classifier by comparing the predicted labels with the true labels and print the accuracy score.
AdaBoostClassifier()
xxxxxxxxxx1class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)Parameters:
base_estimator: The base estimator, also known as the weak learner, to be used in the ensemble. It should be a classifier that supports sample weighting, such as decision trees. The default is a DecisionTreeClassifier(max_depth=1).n_estimators: The number of weak learners to be used in the ensemble. Increasing the number of estimators generally improves the performance, but also increases the computational complexity. The default is 50.learning_rate: The learning rate shrinks the contribution of each weak learner. A smaller learning rate typically requires more estimators to achieve similar performance. The default is 1.0.algorithm: The algorithm parameter specifies the boosting algorithm to use. It can take two values: 'SAMME' or 'SAMME.R'. 'SAMME' is the original AdaBoost algorithm, while 'SAMME.R' is a variant that uses class probabilities for calculating the weighted error. 'SAMME.R' generally performs better. The default is 'SAMME.R'.random_state: The random_state parameter sets the random seed for reproducible results. It is used to initialize the random number generator. The default is None.
Methods:
fit(X, y): Trains the AdaBoost classifier on the given training dataXand target labelsy.predict(X): Predicts the class labels for the input dataXusing the trained AdaBoost classifier.predict_proba(X): Returns the class probabilities for the input dataX. This method is available only if the base estimator supports probability estimation.score(X, y): Returns the mean accuracy on the given test data and labels. It calculates the accuracy of the AdaBoost classifier by comparing the predicted labels with the true labels.
The AdaBoostClassifier is trained by iteratively fitting weak learners to the training data, where each subsequent learner focuses more on the instances that were misclassified by previous learners. The final classification is determined by a weighted majority vote of the weak learners.