AFML 金融数据结构
本文关于金融数据结构的类型、柱线结构进行介绍
第二章 金融数据结构
2.1 动机
2.2 数据类型
2.3 Bars
参考资料:
第二章 金融数据结构
2.1 动机
目标:处理非结构性金融数据,转化成适用于 ML 模型的结构性数据
2.2 数据类型
从左至右复杂度依次增加

2.2.1 基本面数据
大多数是会计数据,按季度汇报。易于出错的是,我们往往忽略了一个事实,分析只能建立在数据公开发表之后(数据发布日期),初学者常见的错误是假设此数据是在报告期末发布
在使用基本面数据时需注意数据发布日期 (release date) 和季度报告截止日期 (quarter-end reporting period) 不一样!前者一般晚于后者 6 周,有时个股的发布日期各不相同。
举例说明:
对茅台 2018 年第一季度 (Q2) 来说,发布日期 (2018-08-02) 才是最重要的日期,因为只有发布之后大家才知道基本面数据值 (比如每股收益 EPS),用报告截止日期 (2018-06-30) 就会引进前视偏差 (look-ahead bias),因此在 2018-06-30 那天数据没有发布给大众,大众根本不知道 Q2 的 EPS 是多少。
下图展示了茅台 2018 年到 2019 年 Q1 的数据发布日期和报告截止日期。
另一方面,对于基本面数据,很常见的一种情况是回填(backfilled)或者复位(reinstated)。
- 回填:缺失值被填充,尽管那些值在那时并不知道
- 复位:不正确的值发布后,经过更改成为正确的值
问题在于,正确的值往往是在后面呗改正过来,而在首次发布时是错误的,所以数据供应商往往会储存多个发布日期和对应的变量值来避免这个问题。比如:我们通常有三个对于单季度GDP的发布值:最初发布值和两个月度修改值。
基本面数据是非常规则的并且是低频的。而且想要过度从其中挖掘其价值显然是不可能的,因为这些数据基本在市场是公开的。但是,在把其和其他数据类型相结合之后可能还是很有用的。
2.2.2 市场数据
市场数据包含了发生在交易所的所有交易活动的数据。每个交易者都在交易所或多或少留下了一些自己的特征线索供我们预测竞争者的下一动作。市场数据 (Market Data) 包含交易所有类型产品时收集到的数据,包括现货价格 (spot price)、期货价格 (futures price)、利率 (interest rate)、汇率 (exchange rate)、波动率 (volatility)、成交量 (volume) 等等。
在交易中,市场数据以限价定单簿 (limitorder book, LOB) 的形式呈现。每个市场参与者都可从中看到订单信息 (order information)。
以阿里巴巴股票 (BABA) 为例的 LOB 如下图所示。
在 LOB 中,卖家看 Bid,买家看 Ask。LOB 里面有四个重要参数,合称为最佳买卖报价 (Best Bid and Offer, BBO),分别是
- 买价 (bid price):卖家可以卖到的最高价 (160 美元)
- 买量 (bid quantity):卖家可以卖的数量 (500 股)
- 卖价 (ask price):买家可以买到的最低价 (161 美元)
- 卖量 (ask quantity):买家可以买的数量 (600 股)
通常数据商提供的是像金融信息交换协议 (Financial Information eXchange, FIX) 类似的原始数据,可以搭建出每个时点的交易账簿 (order book),更精确点的描述是限价定单簿 (limit order book, LOB)。
总结:基本面数据相比,市场数据更规范,而且频率更高,数据量更大,处理起来也更困难,但是价值更大
2.2.3 分析数据(Analytics)
可以看作是基于原生资产的衍生品数据,原生资产可以是基本面数据、市场数据、衍生品,甚至是一些其他的分析数据的集合。重要的不是其含有什么信息,而是其不能从原生资产中直接获取。例如,一些从新的报告和社媒获取的意见等等。
我们可用
- 销量、成本、运营费用等「基本面数据」来评估一个公司的盈利能力和运营质量,并推荐买卖其股票
- 限价定单簿和交易信息等「市场数据」来预测冰山单 (iceberg order) 的大小和概率
- 新闻舆情、财报公告、卫星图像等「另类数据」来做情感分析 (sentiment analysis) 和经营预测
总结:优点在于信号已从原数据中提取,缺点是成本会很高。
2.2.4 另类数据
使用「另类数据」有利有弊
- 优点是没被处理过,也没有为其他使用者提供,因此有很高的价值等待发掘,深度学习里的「计算机视觉」和「自然语言处理」的技术可以用来处理图像和文本数据
- 缺点是「获取昂贵」和「隐私忧患」
2.3 Bars
首先,对于非结构性数据,我们需要对其整合才能使用 ML 算法,从中提取有用的信息,并以一个规则的方式存储,其“行”也叫做 bars。
2.3.1 传统 Bars
2.3.1.1 Time Bars
也就是按照固定的时间间隔来sample,比如,每分钟,每五分钟,每小时等等。
比如,数字货币市场是很动荡的,价格变化飞快,但是长期的交易策略在忽略日内的波动下,可能仍然可以获利,但是中短期的策略依旧要考虑到波动率的问题。
高波动市场下的过、欠采样问题
下面是比特币对应美元的价格波动性(2013-03 ~ 2019-04)的五分钟蜡烛图。
- 绝对价格变化的直方图
- 蜡烛的比例
- 蜡烛造成的价格变化的比例
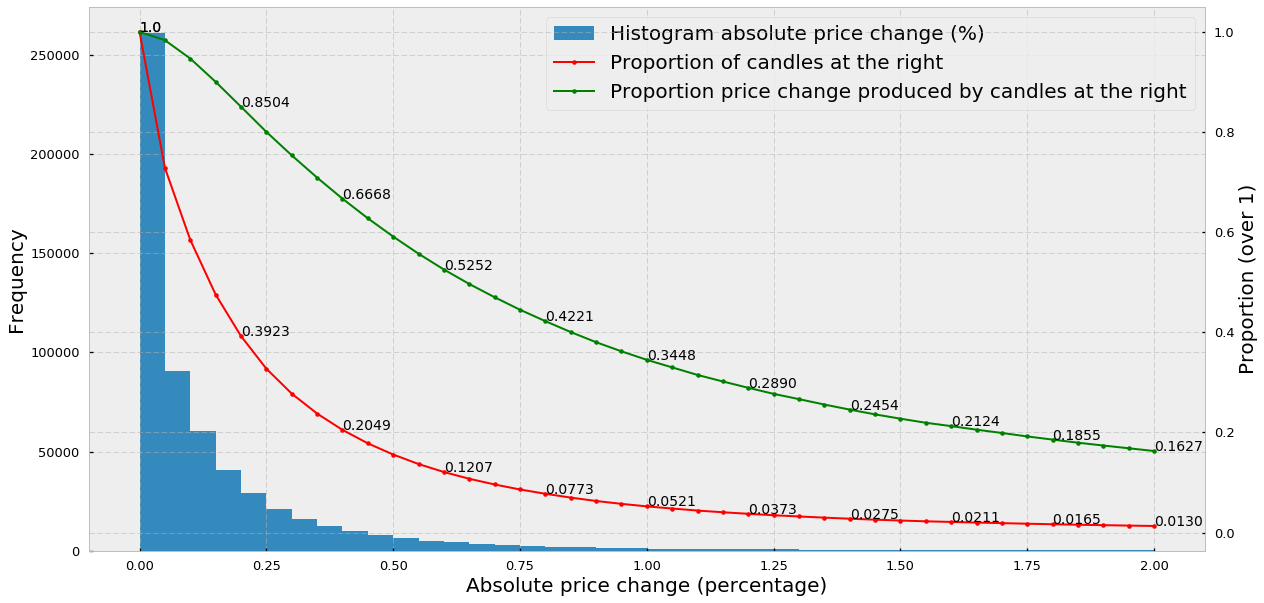
- 大概70%的蜡烛对应的价格变化低于0.25%,其中峰值表示了价格基本没有任何变动
- 20% (0.2049) 的 candlesticks 解释了大概 67% 的价格变化总量
- 而 2% 的 candlestick 竟然解释了 21% 的价格变化总量,这意味着价格变化很大的部分通过 time bars 没有很好地展现出来
所以,得出一个结论:
基于时间的 candlestick 对于低活跃期的数据会过采样,而对于高活跃期的数据会欠采样。
并且,2和3表示大部分的价格变化发生在少数的 candlestick 里,所以如果价格5分钟内改变了10%而且我们用的是5分钟candlestick,算法会忽略其中很多的信息,丧失很多的有效投资机会。
市场不再遵循人类的日间循环
况且,随着科技的发展,自动化成了趋势,我们不在需要严格遵守传统的以人为本的交易时间规则,机器是可以无休止的工作的,而不像人类需要在正常作息的影响下,对于日间循环而带来的交易节奏和交易频率不再敏感。
数据的普遍性不再是优势
每个人都有的数据会造成均态,差异才会产生价值。交易者之间的竞争关系会使得数据的差异性格外的有价值,因为差异性会帮助你提取更多别人不知道的有效信息。
总结一下:
Time bars 是最普遍的,但是它有两个缺点:
- 信息从来都不会均速在市场流动,比如股市开盘交易比临近中午交易要活跃的多。
- 等时抽样得到的序列通常呈现自相关 (serial correlation),异方差 (heteroscedasticity) 和收益非正态 (non-normal return) 等不好的性质。
- 数据不具备差异性,很难获取超额价值
2.3.1.2 Tick Bars
既然基于时间的bars不是最合适的价格数据格式,那么我们可以建立tick bars。
tick数据也称为逐笔数据,衡量了上行或下行的证券价格的每笔交易值
Tick 数据也是交易所对定单薄 (order book) 中进行增加、删除、更新和成交四个操作产生的数据。换句话说,只要在定单薄中买价、买量、卖价和卖量发生变化,那么就产生一个 tick。下图展示了某加密货币的 tick 数据。
所以,我们不想要tick数据,它不能帮我们获取价格的规律,我们需要bar数据,也就是简单地对指定量的ticks进行聚合操作。例如,如果我们要生成100个tick bars,我们要存储所有的交易结果,每次我们收到100次交易,我们就建立一个bar。candlestick用来计算OHLCV。

下面是跟基于时间的 candlestick 对比之下,tick bars 的可视化结果,这里我们展示关于 BTC-USD 交易的4小时和1000tick bars 和在2017-01-21到2017-02-20的所有交易价格。
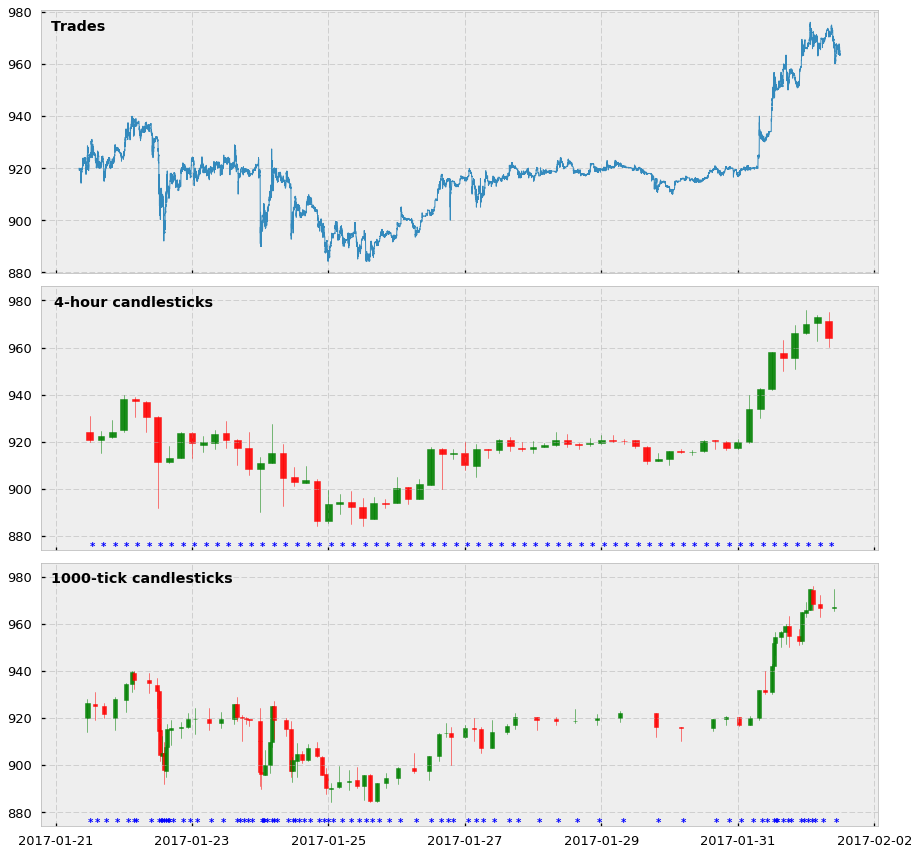
我们看到:
- 是的,tick 的柱线看着 很是丑陋,看起来很混乱、重叠并且难以理解,但是我们要知道人类难以理解,不代表机器难以理解。
- 我们看到这些 “”,可以看出在价格变化剧烈的时候,“” 是很密集的,相反,当价格变动微小时,“” 也比较稀疏。这样解决了高波动市场下 time bars 所带来的问题,避免了在高波动情况下的欠采样和低波动下的过采样问题!
那么,来看看其统计性质,是否会好于 time bars?
我们关注两点:
- 是否有自相关性
- 收益是否满足高斯分布
对于 time bars 和 tick bars,我们定义
- Time-based bar sizes: 1-min, 5-min, 15-min, 30-min, 1-hour, 4-hour, 12-hour, 1-day.
- Tick bar sizes: 50, 100, 200, 500, 1000
自相关性
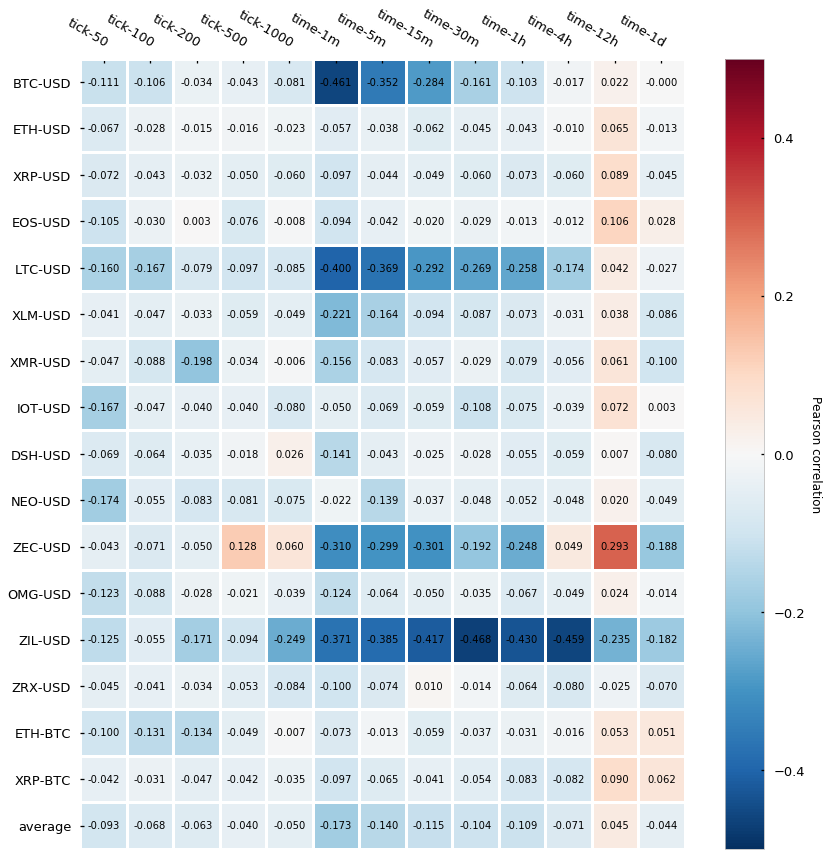
我们使用了 Pearson correlation 来计算自相关性,如果没有自相关性存在的话,就证明我们的序列是互相独立的,满足好的统计性质。
我们看出 tick bars 要比 time bars 有更弱的自相关性,基本接近于0。
再使用一个 Durbin-Watson 检验,检验准则如下:
| Value | Meaning |
|---|---|
| DB-statistic << 2 | positive serial correlation |
| DB-statistic ~ 2 | no first-order correlation |
| DB-statistic >> 2 | negative serial correlation |
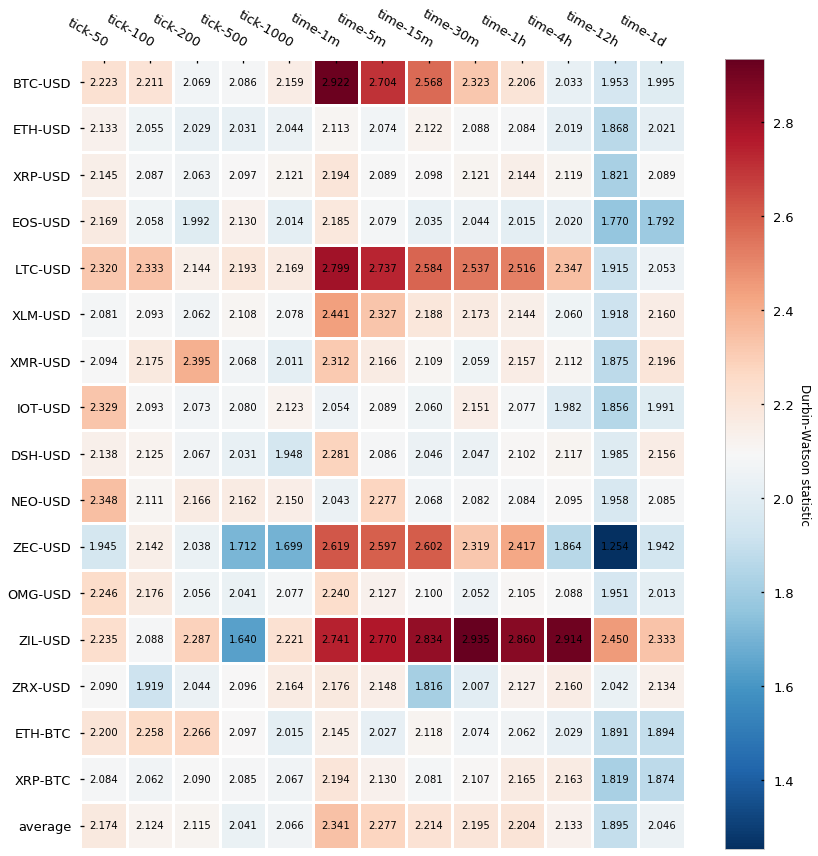
基本跟之前的结果是一致的。
回报是否服从正态分布
JB 统计量反映了偏度和峰度是否满足高斯分布的条件。原假设为满足高斯分布,那么 p-value 应该小于置信度0.05,则满足高斯分布。
W检验,主要检验研究对象是否符合正态分布。
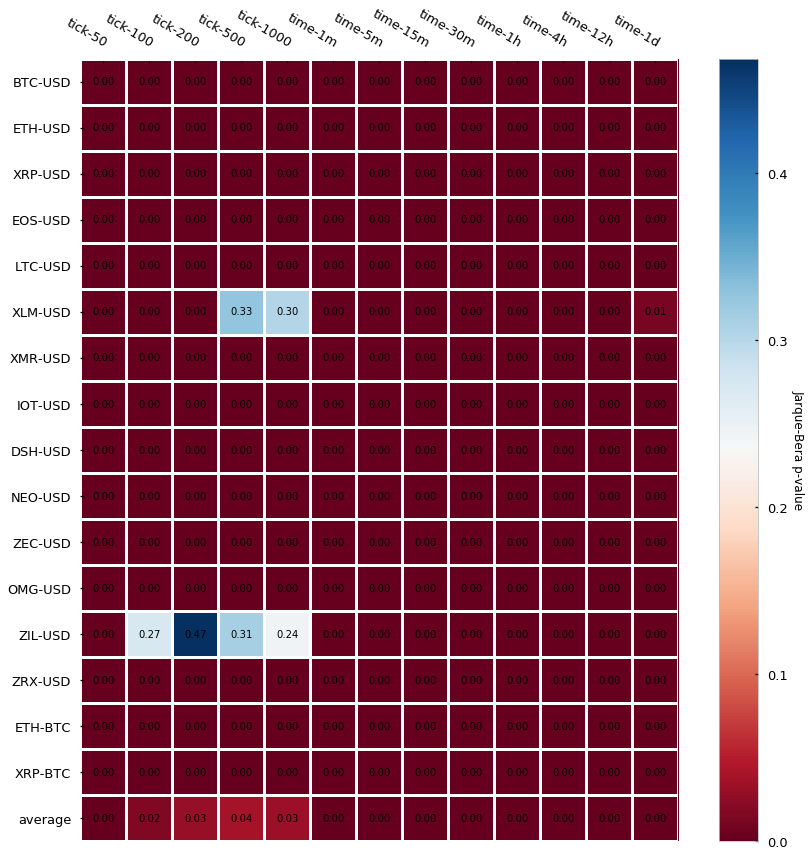
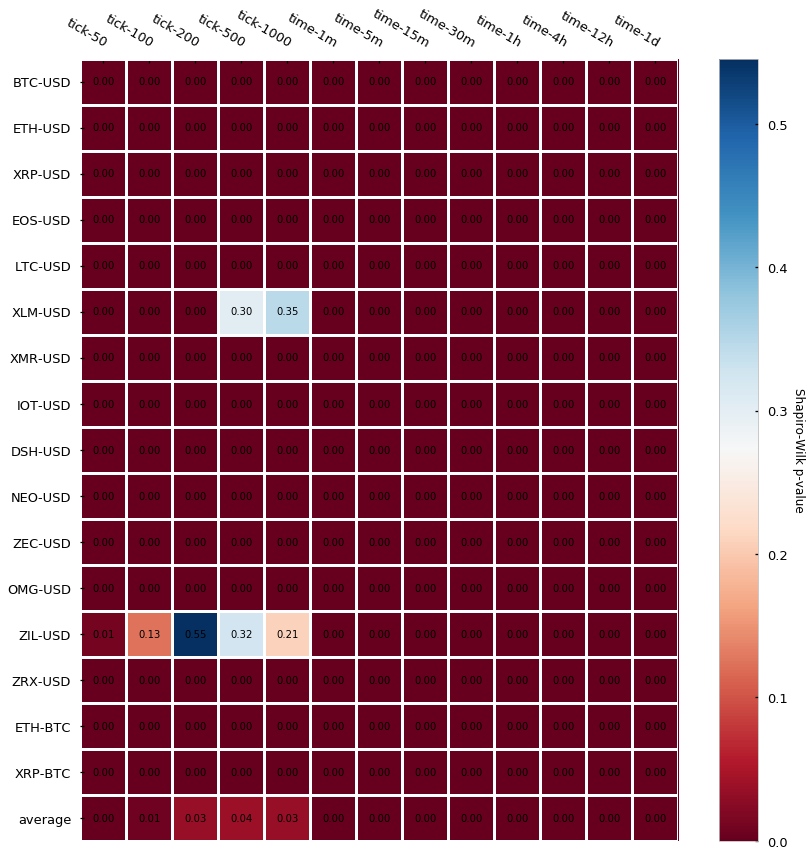
显然,回报的对数化并不满足高斯分布,看一下具体的分布。
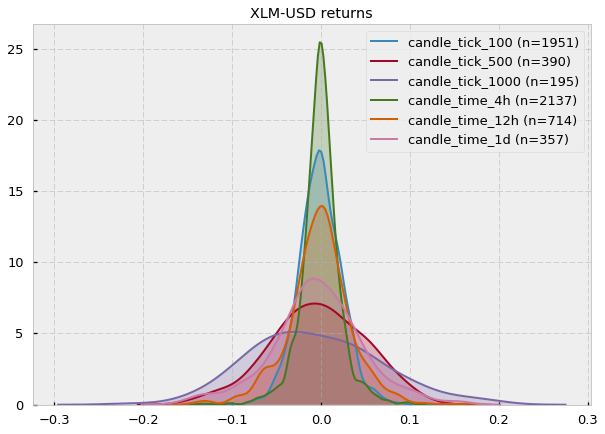
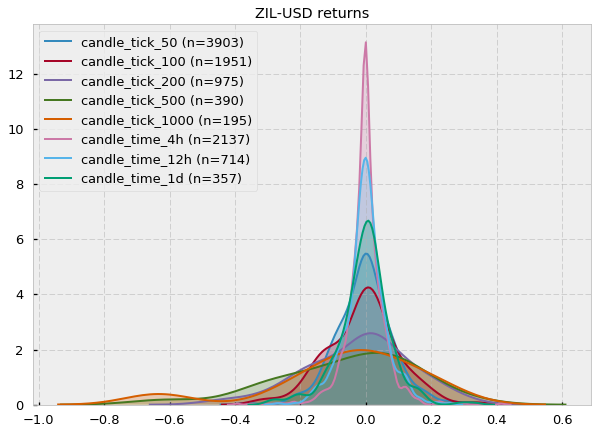
可以看出形状接近于高斯分布,但是偏度和峰度稍有不同,我认为可能是由于抽烟太少造成的。
总结一下:
- Tick 柱线通过对指定数量的 tick 数据的聚合而产生,可用来计算 OHLCV
- 优化了高波动数据的欠采样和低波动数据的过采样问题
- tick 柱线的对数回报的自相关性比 time 柱线的要低
- 两种柱线的对数回报都不遵循高斯分布,但是 tick bars 比 time bars 更接近独立正态同分布 (IID),有更好的统计性质
2.3.1.3 Volume & Dollar Bars
Tick bar 虽说优化了 time bar 的无法提取市场波动性的缺点,但是市场可能发生这种情况,假如有人一笔交易下单买了1000股,那么 1 tick 就记录下来了,但是如果分成 10 单每单 100 股来买的话,其实没区别的,就记录成 10 个 tick,这显然不合理,那么可以用「等量抽样」方法。
x1import numpy as np23# expects a numpy array with trades4# each trade is composed of: [time, price, quantity]5def generate_volumebars(trades, frequency=10):6 times = trades[:,0]7 prices = trades[:,1]8 volumes = trades[:,2]9 ans = np.zeros(shape=(len(prices), 6))10 candle_counter = 011 vol = 012 lasti = 013 for i in range(len(prices)):14 vol += volumes[i]15 if vol >= frequency:16 ans[candle_counter][0] = times[i] # time17 ans[candle_counter][1] = prices[lasti] # open18 ans[candle_counter][2] = np.max(prices[lasti:i+1]) # high19 ans[candle_counter][3] = np.min(prices[lasti:i+1]) # low20 ans[candle_counter][4] = prices[i] # close21 ans[candle_counter][5] = np.sum(volumes[lasti:i+1]) # volume22 candle_counter += 123 lasti = i+124 vol = 025 return ans[:candle_counter]等量抽样是将 tick 数据转换为 volume bars,以每段时间含「固定成交量」的前提下中抽样得到 (比如固定每 1000 股阿里巴巴,每 200 手玉米期货进行一次抽样)。
虽说,等量抽样也能根据市场活跃度来同步抽样,但是他们对于活跃度的理解是不同的,volume bar 把活跃度定义为交易所中交易的资产的数量,也就是标的资产的交易量。
有时候交易的笔数会欺骗人,可能有些人反复下一些很小的单来影响市场的情绪,从而隐藏交易量的总量来引起误导。那么 volume bar 不管交易的数量或者序列,它只关心这些交易的总交易量。
但是,它的问题在于随着时间推移,如果市场价格波动很大的话,交易量的变化并不会说明问题,假设迅雷股票在 6 个月内从 6 美元涨了 400% 到 24 美元,一开始你买了 1000 股迅雷花了 6000 美元,那么在终止点卖只需要卖 250 股票 (6000 美元) 就能回本。如果按 volume bar 来看,1000 股到 250 股波动很大,但实际上成交额都是 6000 美元。此外,股票的量在分割 (split) 和反向分割 (reverse split) 都会变化很大,但股票的额并没有变。
那么我们这时采用「等额抽样」方法,也就是以每段时间含「固定成交额」的前提下中抽样得到 (比如固定每 10000 美元)。这里的 dollar 泛指交易产品的计价货币 (denominated currency),也可以是欧元、英镑、日元或人民币。
xxxxxxxxxx261import numpy as np23# expects a numpy array with trades4# each trade is composed of: [time, price, quantity]5def generate_dollarbars(trades, frequency=1000):6 times = trades[:,0]7 prices = trades[:,1]8 volumes = trades[:,2]9 ans = np.zeros(shape=(len(prices), 6))10 candle_counter = 011 dollars = 012 lasti = 013 for i in range(len(prices)):14 # 这里做了改动,把volume改成了成交额,并与阈值相比较15 dollars += volumes[i]*prices[i]16 if dollars >= frequency:17 ans[candle_counter][0] = times[i] # time18 ans[candle_counter][1] = prices[lasti] # open19 ans[candle_counter][2] = np.max(prices[lasti:i+1]) # high20 ans[candle_counter][3] = np.min(prices[lasti:i+1]) # low21 ans[candle_counter][4] = prices[i] # close22 ans[candle_counter][5] = np.sum(volumes[lasti:i+1]) # volume23 candle_counter += 124 lasti = i+125 dollars = 026 return ans[:candle_counter]接下来,看看跟传统的 time bar 相比,他们的表现如何。

跟 tick bar 类似,volume bar 和 dollar bar 也看着很乱,但是实际上他们是有效的捕捉了市场波动性。
也来分析一下他们的统计特征。
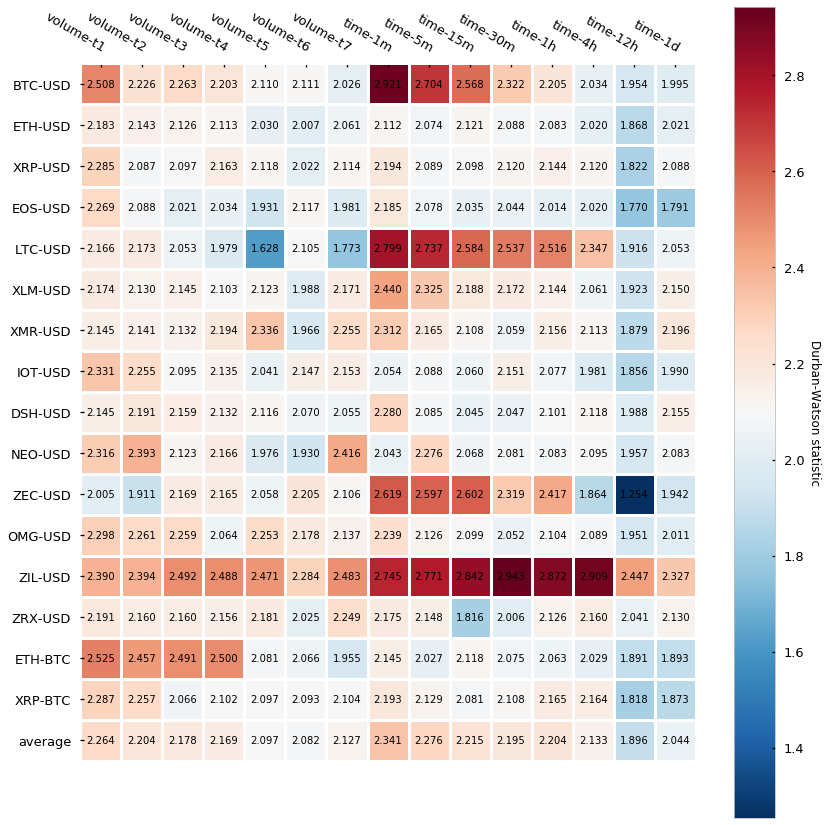
关于 volume bar,我们在 16 个 trading pairs 上使用 7 个 volume size 来展示结果。我们为每种加密货币选择交易量大小的方式是计算每天交换的平均交易量,然后将每日平均交易量除以与 1 天对应的5min,15min,30min,1h,4h,12h相同的比率,并四舍五入。
| t1 | t2 | t3 | t4 | t5 | t6 | T7 | |
|---|---|---|---|---|---|---|---|
| BTCUSD | 80 | 200 | 500 | 1000 | 4000 | 10000 | 20000 |
| DSHUSD | 40 | 100 | 200 | 500 | 2000 | 6000 | 10000 |
| EOSUSD | 20000 | 70000 | 100000 | 200000 | 1000000 | 3000000 | 7000000 |
| ETHBTC | 200 | 600 | 1000 | 2000 | 10000 | 30000 | 60000 |
| ETHUSD | 600 | 1000 | 3000 | 7000 | 30000 | 90000 | 100000 |
| IOTUSD | 60000 | 100000 | 300000 | 700000 | 3000000 | 9000000 | 10000000 |
| LTCUSD | 400 | 1000 | 2000 | 4000 | 10000 | 50000 | 100000 |
| NEOUSD | 1000 | 3000 | 6000 | 10000 | 50000 | 100000 | 300000 |
| OMGUSD | 2000 | 8000 | 10000 | 30000 | 100000 | 400000 | 800000 |
| XLMUSD | 4000 | 10000 | 20000 | 50000 | 200000 | 600000 | 1000000 |
| XMRUSD | 100 | 300 | 600 | 1000 | 4000 | 10000 | 20000 |
| XRPBTC | 40000 | 100000 | 200000 | 400000 | 1000000 | 5000000 | 10000000 |
| XRPUSD | 100000 | 500000 | 1000000 | 2000000 | 8000000 | 20000000 | 50000000 |
| ZECUSD | 50 | 100 | 300 | 600 | 2000 | 7000 | 10000 |
| ZILUSD | 500 | 1000 | 3000 | 6000 | 20000 | 80000 | 100000 |
| ZRXUSD | 2000 | 7000 | 10000 | 20000 | 100000 | 300000 | 700000 |
| t1 | t2 | t3 | t4 | t5 | t6 | t7 | T8 | |
|---|---|---|---|---|---|---|---|---|
| BTCUSD | 30000 | 100000 | 500000 | 1000000 | 2000000 | 9000000 | 20000000 | 50000000 |
| DSHUSD | 2000 | 10000 | 40000 | 80000 | 100000 | 600000 | 1000000 | 3000000 |
| EOSUSD | 20000 | 100000 | 400000 | 800000 | 1000000 | 6000000 | 20000000 | 40000000 |
| ETHUSD | 30000 | 100000 | 400000 | 900000 | 1000000 | 7000000 | 20000000 | 40000000 |
| IOTUSD | 10000 | 60000 | 100000 | 300000 | 700000 | 3000000 | 9000000 | 10000000 |
| LTCUSD | 2000 | 10000 | 30000 | 70000 | 100000 | 600000 | 1000000 | 3000000 |
| NEOUSD | 9000 | 40000 | 100000 | 200000 | 500000 | 2000000 | 6000000 | 10000000 |
| OMGUSD | 4000 | 20000 | 60000 | 100000 | 200000 | 1000000 | 3000000 | 6000000 |
| XLMUSD | 100 | 900 | 2000 | 5000 | 10000 | 40000 | 100000 | 200000 |
| XMRUSD | 2000 | 10000 | 30000 | 60000 | 100000 | 500000 | 1000000 | 3000000 |
| XRPUSD | 10000 | 90000 | 200000 | 500000 | 1000000 | 4000000 | 10000000 | 20000000 |
| ZECUSD | 2000 | 10000 | 30000 | 60000 | 100000 | 500000 | 1000000 | 3000000 |
| ZRXUSD | 300 | 1000 | 5000 | 10000 | 20000 | 90000 | 200000 | 500000 |
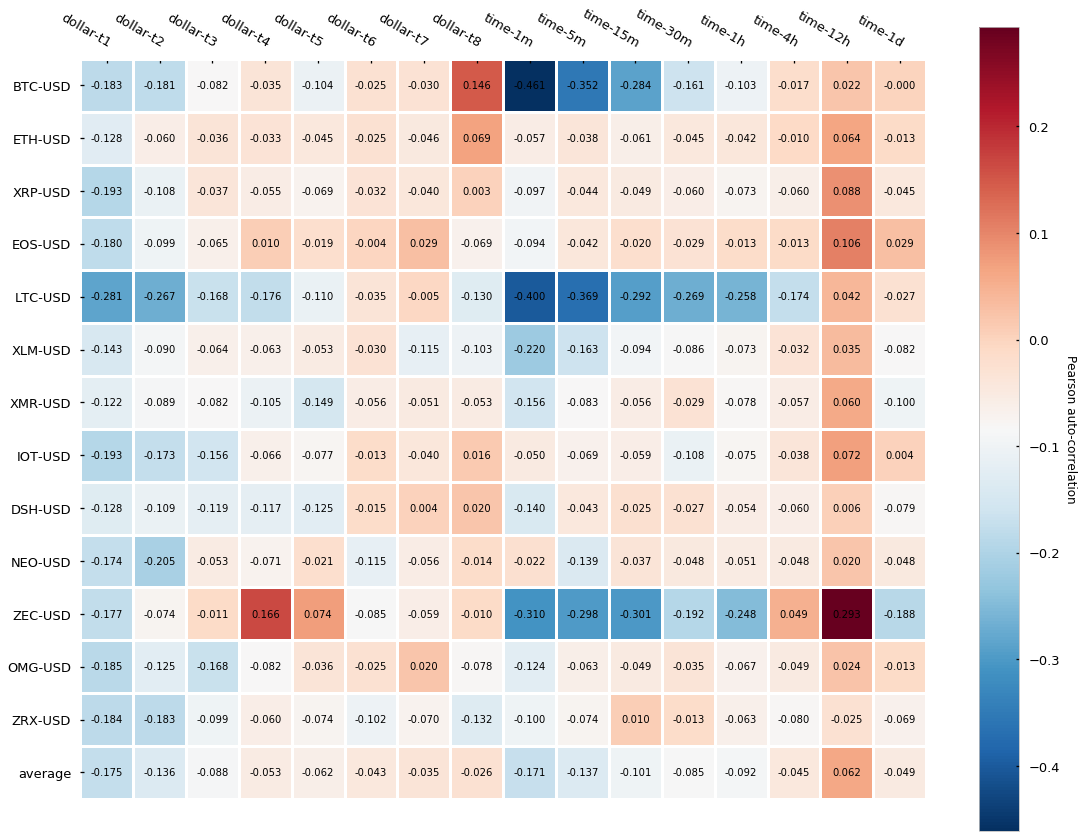
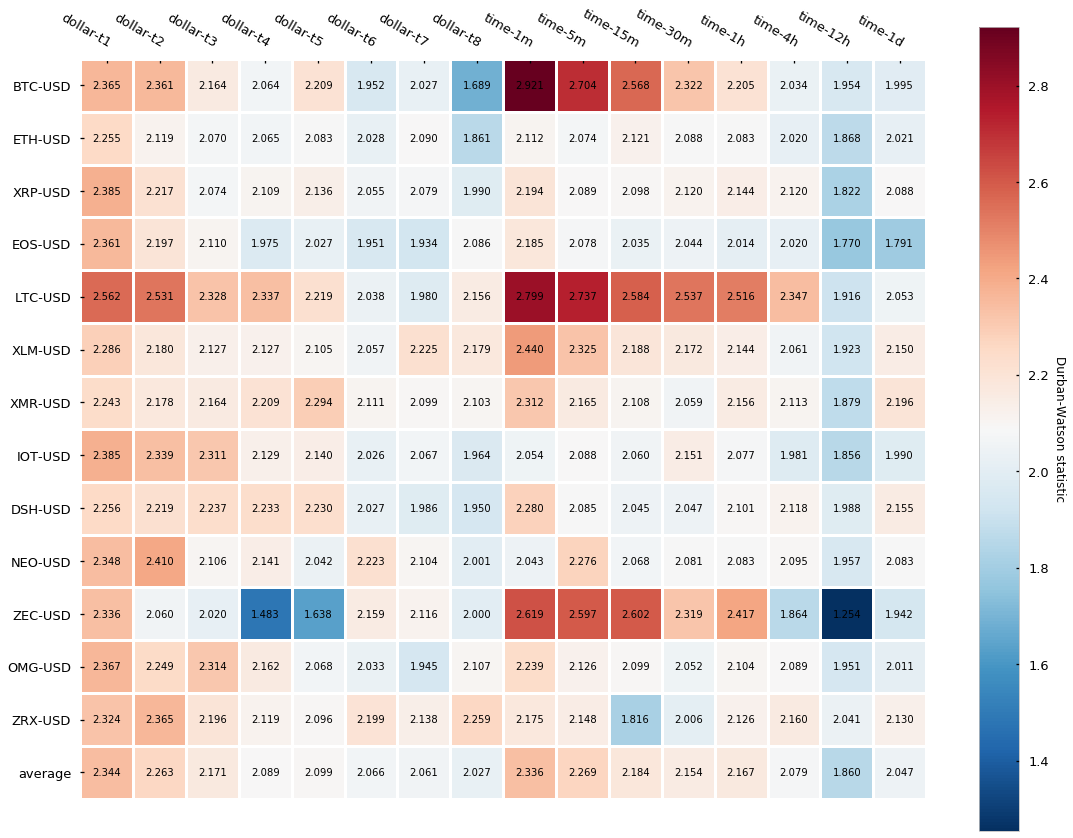
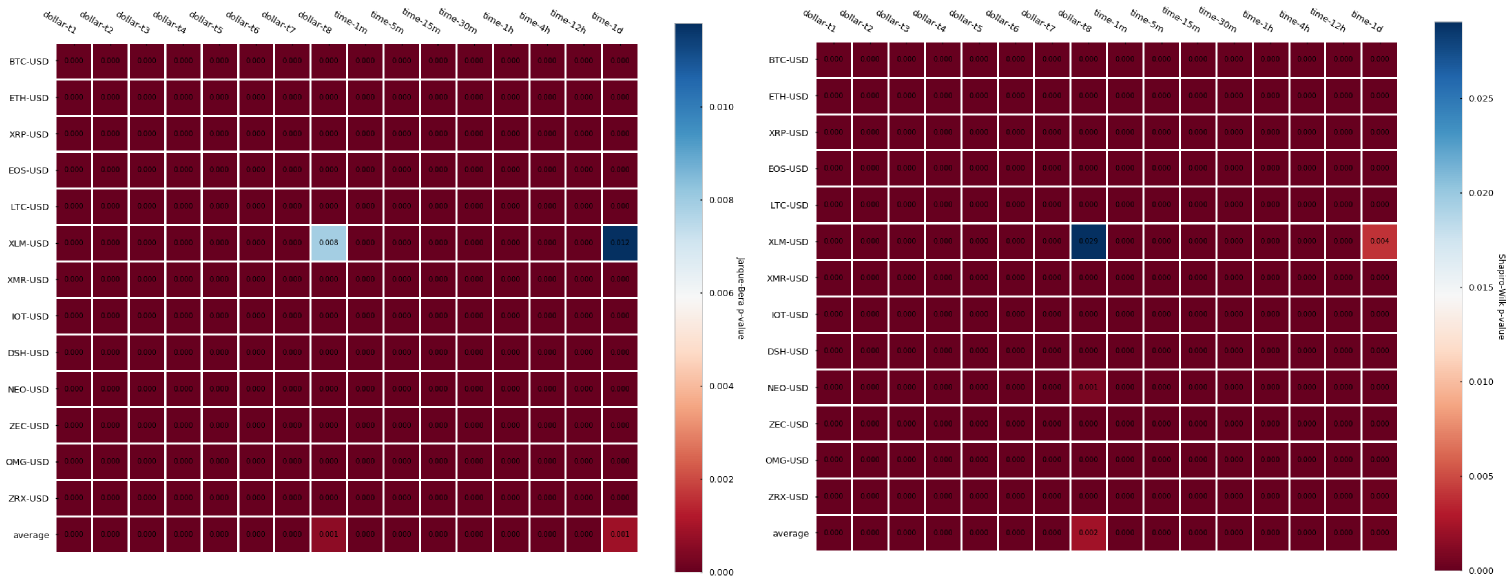
可以看到 dollar bar 并没展示出很好的独立性,也就是相比于 time bar 关于自相关性上没有太多提升。
我们如何对市场活动作出理解?会不会市场会非常活跃,价格会侧向偏移呢?答案是肯定的,尽管通常市场活动活跃与价格大变动之间存在相关性,但这种关系无法得到保证。例如,在某些情况下,较高的 FUD(恐惧,不确定性和疑问)可以激起销量的大幅度上涨,而价格变化却很小。同样,在加密货币市场中,冲洗交易绝对不是不常见的。这些举动涉及到自我交易(买方和卖方是同一个人),这再次激起了交易量的巨大峰值,而价格却几乎没有变化。
所以为了排除此类因素,我们看一下对于每一种 bar 的日内柱线价格变化的分布。
intra-candle variation = (high-low)/high
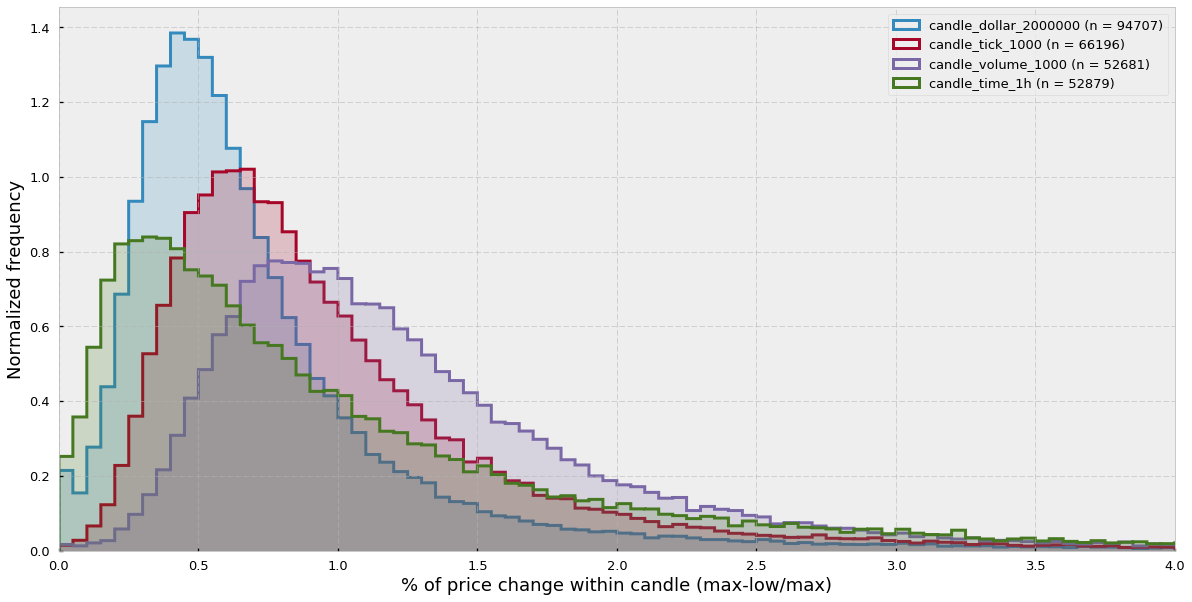
可以看出 time bar 更向 0 偏移,并且尾部很长,而其他的都能在价格波动较大时有效的抽取更多样本。
下图展示了 bar 的日频率以及资产价格和市场活跃度是如何影响 sampling rate 的。
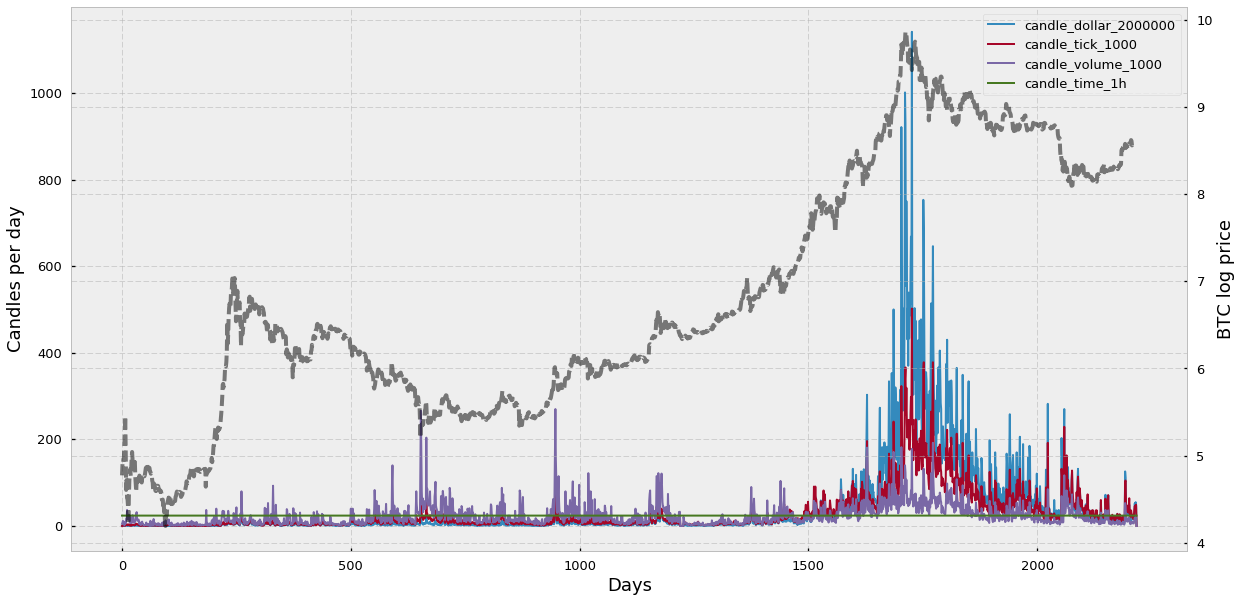
可以看到,time bar 是以同样的比率采样的,每天 24 个 bar,而其他的都根据价格的变化而改变(灰色的线)。
总结一下:
- volume bar 解决了 tick bar 的局限性,防止下单分割的不合理性,按照规定的固定的成交量来采样
- Dollar bar 解决了 volume bar 的市场价格波动剧烈导致 volume 变化随着重新估值而变得不显著的问题,按照规定的固定的资产交易价值来采样
- 都能在高活跃度市场下更多的采集样本
- volume bar 自相关性比 time bar 弱
- Dollar bar 自相关性没有比 time bar 有显著提升;注意:大多数 dollar bar 的数量可能集中于一小段时间,并且平均的自相关度可能会更高一些,这是因为 bar 之间距离太近了。
- 对数回报都不遵从高斯分布
- volume bar 的采样率是除了 time bar 最为稳定的
- Dollar bar 的采样率可能随着超高的 volume 而激增
2.3.2 信息驱动 bar
2.3.2.1 Imbalance bars
构建信息驱动 bar 在更多信息进入市场时进行更频繁的抽样。当买卖不均衡时,市场参与者之间的信息差也变大,市场会出现知情交易者(informed trader)。在抽样时考虑买卖不均衡,我们可以在价格达到新的均衡水平之前做出决定。信息驱动 bar 也分两种:
- Imbalance Bars (IB) 系列:TIB, VIB, DIB
- Runs Bars (RB) 系列:TRB, VRB, DRB
上面缩写里的 T, V, D 代表的是 tick, volume, dollar。
对每个时点 ,我们有价格 和成交量 两个序列
- 价格序列 =
- 成交量序列 =
基于「价量」序列,我们定义一个「衡量买卖均衡度」的变量
- 如果价格比前一次交易价格高,我们把这个tick设为1
- 反正,设为-1
- 价格相等,我们令价格等于前一次交易的价格

只是在衡量在时间点 t 的均衡度,那么累积均衡度就是累加所有的 ,得到
第 1 行套用 定义。
第 2 行将索引 T 扩展到 +∞,并添加指标函数 1{T>t-1}。
第 3 行将期望符号和累加符号互换。
第 4 行提出公共因子 。
第 5 行用到 E[1(A)] = P(A) 性质。
第 6 行将索引从 1 移到 0。
第 7 行根据 定义。
第 8 行展开 表达式。
第 9-10 行化简公式。
上式中
- 是每个 bar 含有 tick 数的期望
- 是该 tick 被划分为「买」的无条件概率
- 是该 tick 被划分为「卖」的无条件概率
买卖的无条件概率加起来为 1,即 ,因此可将上式化简成
在实操中
- = 历史数据 T 的指数加权平均值 (exponentially-weighted moving average, EMA)
- = 历史数据「买单占比」的 EMA
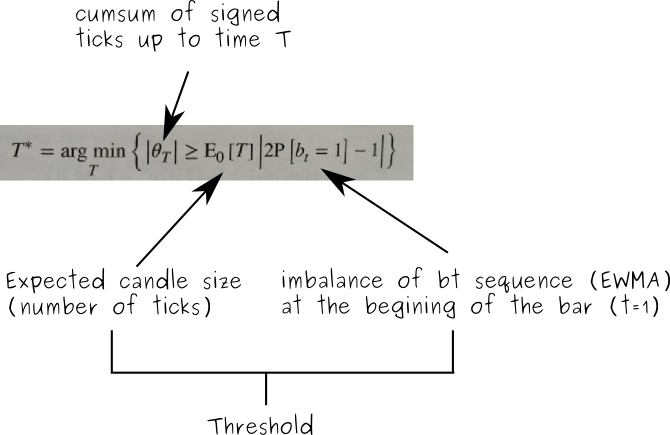
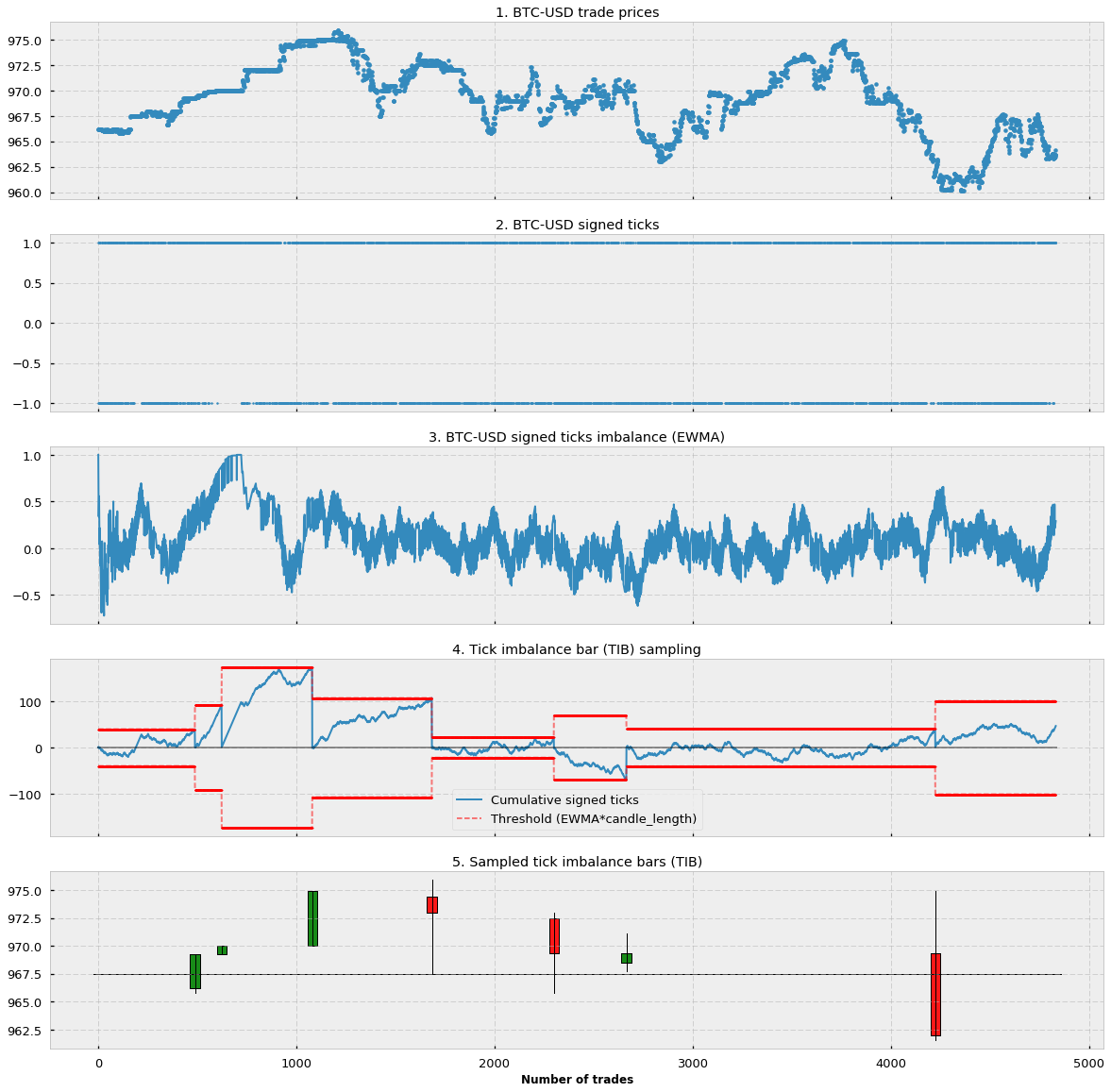
由于 的计算应该采用前面 T 个 bars 的EWMA。然而 bar 的大小,也就是每个 bar 含有的 tick 的数量会在几次迭代后激增。是因为随着阈值的增加,需要更多的 signed ticks 来达到阈值,反而使得 bar 的期望值在正向循环中不断增加,最终到无穷大。可以尝试以下几个方法:
- 限制最大的 candle size
- 更正 candle size
柱线的大小其实也是一个影响时序数据能否达到我们的预期,也就是超过所设定的阈值,作为信号出现。如果我们设定每个柱线的大小过大的话,也就是说我们的 signed bar 会需要更多的数据来确认+1 还是 -1,从而会给模型带来更大的挑战。
2.3.2.2 VIB/DIB
那么 VIB 和 DIB 其实就是 TIB 的一个延伸概念,那么我们只不过在 的基础上,乘上一个
这里的 可以代表 VIB 中的交易量,也可以表示 DIB 中的对应资产的交易货币价值。
那么,接下来需要计算 在 bar 开始时的期望
那么,我们还是用 EWMA 来估计上面的参数 和 ,并满足
统计性质分析如下:
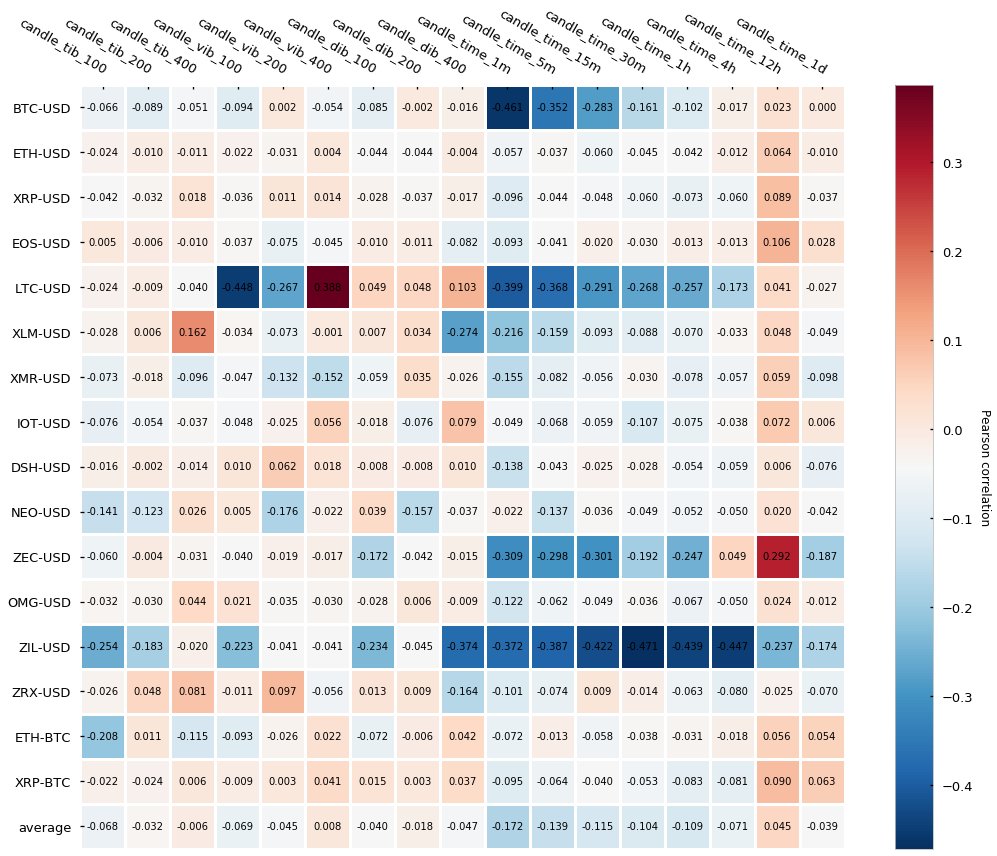
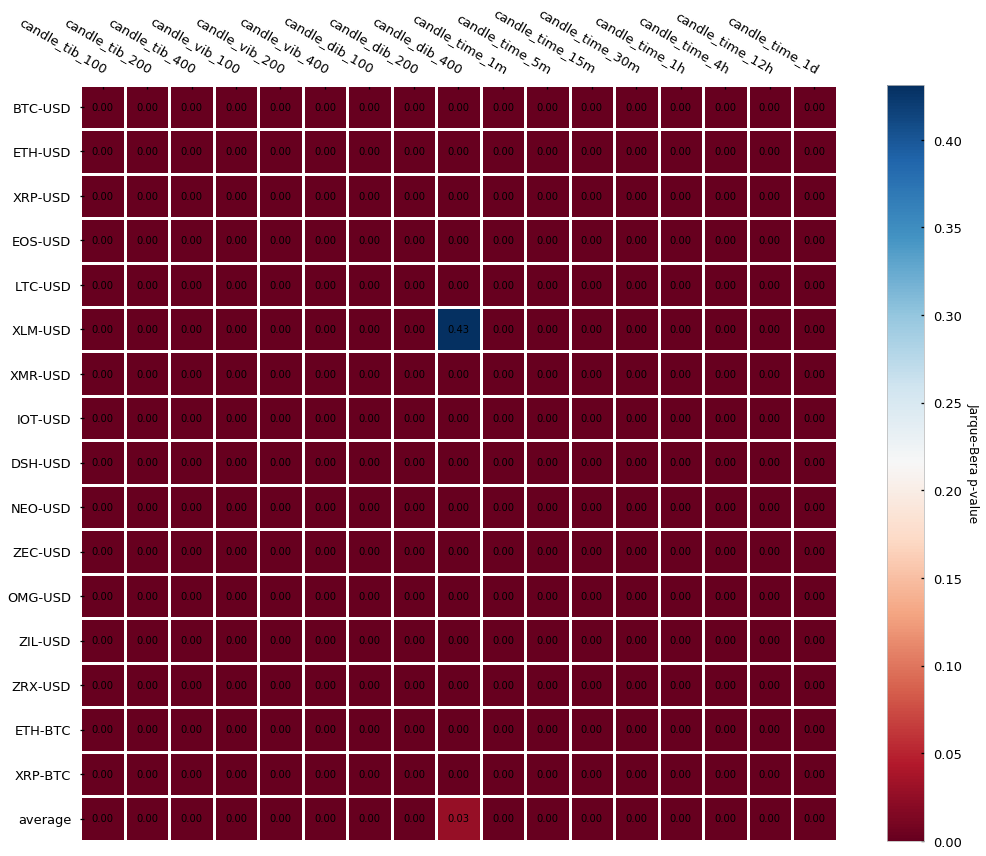
总结一下:
- 不均衡性由了signed ticks 的累积和的大小所决定
- signed ticks 的确定来自于 tick rule
- 在 imbalance 超过我们所设置的阈值时,开始采样
- imbalance bar 的目的是早一点检测到市场在抵达均衡点之前的价格走向
- imbalance bar 有更低的自相关性并且不遵从正态分布
2.3.2.3 Tick Runs Bars
这里我们不考虑不均衡度的问题了,在大型的交易者眼里,更看重的整个交易量中的买方序列的监测,一旦正向或者反向的 tick 累积到一定程度超出阈值时,模型开始采样。
我们定义当前的序列长度为:
接下来,我们计算 bar 开始的时候的 的期望
同样用 EWMA 来估计 和 。
并定义 TRB 为
其中 tick 数量的期望由 确定
2.3.2.4 VRB/DRB
同理,我们对上面的公式做一些改动
其中, 代表交易量或者对应的交易货币数量,这取决于采用 VRB 还是 DRB。
那么,我们计算 bar 开始的时候的 的期望
并定义 VRB/DRB 为